Kubernetes Cluster API
Cluster API is a Kubernetes sub-project focused on providing declarative APIs and tooling to simplify provisioning, upgrading, and operating multiple Kubernetes clusters.
Started by the Kubernetes Special Interest Group (SIG) Cluster Lifecycle, the Cluster API project uses Kubernetes-style APIs and patterns to automate cluster lifecycle management for platform operators. The supporting infrastructure, like virtual machines, networks, load balancers, and VPCs, as well as the Kubernetes cluster configuration are all defined in the same way that application developers operate deploying and managing their workloads. This enables consistent and repeatable cluster deployments across a wide variety of infrastructure environments.
Getting started
Using Cluster API v1alpha3? See the legacy documentation.
Why build Cluster API?
Kubernetes is a complex system that relies on several components being configured correctly to have a working cluster. Recognizing this as a potential stumbling block for users, the community focused on simplifying the bootstrapping process. Today, over 100 Kubernetes distributions and installers have been created, each with different default configurations for clusters and supported infrastructure providers. SIG Cluster Lifecycle saw a need for a single tool to address a set of common overlapping installation concerns and started kubeadm.
Kubeadm was designed as a focused tool for bootstrapping a best-practices Kubernetes cluster. The core tenet behind the kubeadm project was to create a tool that other installers can leverage and ultimately alleviate the amount of configuration that an individual installer needed to maintain. Since it began, kubeadm has become the underlying bootstrapping tool for several other applications, including Kubespray, Minikube, kind, etc.
However, while kubeadm and other bootstrap providers reduce installation complexity, they don’t address how to manage a cluster day-to-day or a Kubernetes environment long term. You are still faced with several questions when setting up a production environment, including:
- How can I consistently provision machines, load balancers, VPC, etc., across multiple infrastructure providers and locations?
- How can I automate cluster lifecycle management, including things like upgrades and cluster deletion?
- How can I scale these processes to manage any number of clusters?
SIG Cluster Lifecycle began the Cluster API project as a way to address these gaps by building declarative, Kubernetes-style APIs, that automate cluster creation, configuration, and management. Using this model, Cluster API can also be extended to support any infrastructure provider (AWS, Azure, vSphere, etc.) or bootstrap provider (kubeadm is default) you need. See the growing list of available providers.
Goals
- To manage the lifecycle (create, scale, upgrade, destroy) of Kubernetes-conformant clusters using a declarative API.
- To work in different environments, both on-premises and in the cloud.
- To define common operations, provide a default implementation, and provide the ability to swap out implementations for alternative ones.
- To reuse and integrate existing ecosystem components rather than duplicating their functionality (e.g. node-problem-detector, cluster autoscaler, SIG-Multi-cluster).
- To provide a transition path for Kubernetes lifecycle products to adopt Cluster API incrementally. Specifically, existing cluster lifecycle management tools should be able to adopt Cluster API in a staged manner, over the course of multiple releases, or even adopting a subset of Cluster API.
Non-goals
- To add these APIs to Kubernetes core (kubernetes/kubernetes).
- This API should live in a namespace outside the core and follow the best practices defined by api-reviewers, but is not subject to core-api constraints.
- To manage the lifecycle of infrastructure unrelated to the running of Kubernetes-conformant clusters.
- To force all Kubernetes lifecycle products (kops, kubespray, GKE, AKS, EKS, IKS etc.) to support or use these APIs.
- To manage non-Cluster API provisioned Kubernetes-conformant clusters.
- To manage a single cluster spanning multiple infrastructure providers.
- To configure a machine at any time other than create or upgrade.
- To duplicate functionality that exists or is coming to other tooling, e.g., updating kubelet configuration (c.f. dynamic kubelet configuration), or updating apiserver, controller-manager, scheduler configuration (c.f. component-config effort) after the cluster is deployed.
🤗 Community, discussion, contribution, and support
Cluster API is developed in the open, and is constantly being improved by our users, contributors, and maintainers. It is because of you that we are able to automate cluster lifecycle management for the community. Join us!
If you have questions or want to get the latest project news, you can connect with us in the following ways:
- Chat with us on the Kubernetes Slack in the #cluster-api channel
- Subscribe to the SIG Cluster Lifecycle Google Group for access to documents and calendars
- Participate in the conversations on Kubernetes Discuss
- Join our Cluster API working group sessions where we share the latest project news, demos, answer questions, and triage issues
- Weekly on Wednesdays @ 10:00 PT on Zoom
- Previous meetings: [ notes | recordings ]
Pull Requests and feedback on issues are very welcome! See the issue tracker if you’re unsure where to start, especially the Good first issue and Help wanted tags, and also feel free to reach out to discuss.
See also our contributor guide and the Kubernetes community page for more details on how to get involved.
Code of conduct
Participation in the Kubernetes community is governed by the Kubernetes Code of Conduct.
Quick Start
In this tutorial we’ll cover the basics of how to use Cluster API to create one or more Kubernetes clusters.
Installation
Common Prerequisites
Install and/or configure a Kubernetes cluster
Cluster API requires an existing Kubernetes cluster accessible via kubectl. During the installation process the Kubernetes cluster will be transformed into a management cluster by installing the Cluster API provider components, so it is recommended to keep it separated from any application workload.
It is a common practice to create a temporary, local bootstrap cluster which is then used to provision a target management cluster on the selected infrastructure provider.
Choose one of the options below:
-
Existing Management Cluster
For production use-cases a “real” Kubernetes cluster should be used with appropriate backup and DR policies and procedures in place. The Kubernetes cluster must be at least v1.19.1.
export KUBECONFIG=<...> -
Kind
kind can be used for creating a local Kubernetes cluster for development environments or for the creation of a temporary bootstrap cluster used to provision a target management cluster on the selected infrastructure provider.
The installation procedure depends on the version of kind; if you are planning to use the Docker infrastructure provider, please follow the additional instructions in the dedicated tab:
Create the kind cluster:
kind create clusterTest to ensure the local kind cluster is ready:
kubectl cluster-infoRun the following command to create a kind config file for allowing the Docker provider to access Docker on the host:
cat > kind-cluster-with-extramounts.yaml <<EOF kind: Cluster apiVersion: kind.x-k8s.io/v1alpha4 nodes: - role: control-plane extraMounts: - hostPath: /var/run/docker.sock containerPath: /var/run/docker.sock EOFThen follow the instruction for your kind version using
kind create cluster --config kind-cluster-with-extramounts.yamlto create the management cluster using the above file.
Install clusterctl
The clusterctl CLI tool handles the lifecycle of a Cluster API management cluster.
Install clusterctl binary with curl on linux
Download the latest release; on linux, type:
curl -L https://github.com/kubernetes-sigs/cluster-api/releases/download/v0.4.8/clusterctl-linux-amd64 -o clusterctl
Make the clusterctl binary executable.
chmod +x ./clusterctl
Move the binary in to your PATH.
sudo mv ./clusterctl /usr/local/bin/clusterctl
Test to ensure the version you installed is up-to-date:
clusterctl version
Install clusterctl binary with curl on macOS
Download the latest release; on macOS, type:
curl -L https://github.com/kubernetes-sigs/cluster-api/releases/download/v0.4.8/clusterctl-darwin-amd64 -o clusterctl
Or if your Mac has an M1 CPU (”Apple Silicon”):
curl -L https://github.com/kubernetes-sigs/cluster-api/releases/download/v0.4.8/clusterctl-darwin-arm64 -o clusterctl
Make the clusterctl binary executable.
chmod +x ./clusterctl
Move the binary in to your PATH.
sudo mv ./clusterctl /usr/local/bin/clusterctl
Test to ensure the version you installed is up-to-date:
clusterctl version
Install clusterctl with homebrew on macOS and linux
Install the latest release using homebrew:
brew install clusterctl
Test to ensure the version you installed is up-to-date:
clusterctl version
Initialize the management cluster
Now that we’ve got clusterctl installed and all the prerequisites in place, let’s transform the Kubernetes cluster
into a management cluster by using clusterctl init.
The command accepts as input a list of providers to install; when executed for the first time, clusterctl init
automatically adds to the list the cluster-api core provider, and if unspecified, it also adds the kubeadm bootstrap
and kubeadm control-plane providers.
Initialization for common providers
Depending on the infrastructure provider you are planning to use, some additional prerequisites should be satisfied before getting started with Cluster API. See below for the expected settings for common providers.
Download the latest binary of clusterawsadm from the AWS provider releases and make sure to place it in your path.
The clusterawsadm command line utility assists with identity and access management (IAM) for Cluster API Provider AWS.
export AWS_REGION=us-east-1 # This is used to help encode your environment variables
export AWS_ACCESS_KEY_ID=<your-access-key>
export AWS_SECRET_ACCESS_KEY=<your-secret-access-key>
export AWS_SESSION_TOKEN=<session-token> # If you are using Multi-Factor Auth.
# The clusterawsadm utility takes the credentials that you set as environment
# variables and uses them to create a CloudFormation stack in your AWS account
# with the correct IAM resources.
clusterawsadm bootstrap iam create-cloudformation-stack
# Create the base64 encoded credentials using clusterawsadm.
# This command uses your environment variables and encodes
# them in a value to be stored in a Kubernetes Secret.
export AWS_B64ENCODED_CREDENTIALS=$(clusterawsadm bootstrap credentials encode-as-profile)
# Finally, initialize the management cluster
clusterctl init --infrastructure aws
See the AWS provider prerequisites document for more details.
For more information about authorization, AAD, or requirements for Azure, visit the Azure provider prerequisites document.
export AZURE_SUBSCRIPTION_ID="<SubscriptionId>"
# Create an Azure Service Principal and paste the output here
export AZURE_TENANT_ID="<Tenant>"
export AZURE_CLIENT_ID="<AppId>"
export AZURE_CLIENT_SECRET="<Password>"
# Base64 encode the variables
export AZURE_SUBSCRIPTION_ID_B64="$(echo -n "$AZURE_SUBSCRIPTION_ID" | base64 | tr -d '\n')"
export AZURE_TENANT_ID_B64="$(echo -n "$AZURE_TENANT_ID" | base64 | tr -d '\n')"
export AZURE_CLIENT_ID_B64="$(echo -n "$AZURE_CLIENT_ID" | base64 | tr -d '\n')"
export AZURE_CLIENT_SECRET_B64="$(echo -n "$AZURE_CLIENT_SECRET" | base64 | tr -d '\n')"
# Settings needed for AzureClusterIdentity used by the AzureCluster
export AZURE_CLUSTER_IDENTITY_SECRET_NAME="cluster-identity-secret"
export CLUSTER_IDENTITY_NAME="cluster-identity"
export AZURE_CLUSTER_IDENTITY_SECRET_NAMESPACE="default"
# Create a secret to include the password of the Service Principal identity created in Azure
# This secret will be referenced by the AzureClusterIdentity used by the AzureCluster
kubectl create secret generic "${AZURE_CLUSTER_IDENTITY_SECRET_NAME}" --from-literal=clientSecret="${AZURE_CLIENT_SECRET}"
# Finally, initialize the management cluster
clusterctl init --infrastructure azure
export DIGITALOCEAN_ACCESS_TOKEN=<your-access-token>
export DO_B64ENCODED_CREDENTIALS="$(echo -n "${DIGITALOCEAN_ACCESS_TOKEN}" | base64 | tr -d '\n')"
# Initialize the management cluster
clusterctl init --infrastructure digitalocean
The Docker provider does not require additional prerequisites. You can run:
clusterctl init --infrastructure docker
# Create the base64 encoded credentials by catting your credentials json.
# This command uses your environment variables and encodes
# them in a value to be stored in a Kubernetes Secret.
export GCP_B64ENCODED_CREDENTIALS=$( cat /path/to/gcp-credentials.json | base64 | tr -d '\n' )
# Finally, initialize the management cluster
clusterctl init --infrastructure gcp
# The username used to access the remote vSphere endpoint
export VSPHERE_USERNAME="vi-admin@vsphere.local"
# The password used to access the remote vSphere endpoint
# You may want to set this in ~/.cluster-api/clusterctl.yaml so your password is not in
# bash history
export VSPHERE_PASSWORD="admin!23"
# Finally, initialize the management cluster
clusterctl init --infrastructure vsphere
For more information about prerequisites, credentials management, or permissions for vSphere, see the vSphere project.
# Initialize the management cluster
clusterctl init --infrastructure openstack
Please visit the Metal3 project.
In order to initialize the Packet Provider you have to expose the environment
variable PACKET_API_KEY. This variable is used to authorize the infrastructure
provider manager against the Packet API. You can retrieve your token directly
from the Packet Portal.
export PACKET_API_KEY="34ts3g4s5g45gd45dhdh"
clusterctl init --infrastructure packet
The output of clusterctl init is similar to this:
Fetching providers
Installing cert-manager Version="v1.5.3"
Waiting for cert-manager to be available...
Installing Provider="cluster-api" Version="v0.4.0" TargetNamespace="capi-system"
Installing Provider="bootstrap-kubeadm" Version="v0.4.0" TargetNamespace="capi-kubeadm-bootstrap-system"
Installing Provider="control-plane-kubeadm" Version="v0.4.0" TargetNamespace="capi-kubeadm-control-plane-system"
Installing Provider="infrastructure-docker" Version="v0.4.0" TargetNamespace="capd-system"
Your management cluster has been initialized successfully!
You can now create your first workload cluster by running the following:
clusterctl generate cluster [name] --kubernetes-version [version] | kubectl apply -f -
Create your first workload cluster
Once the management cluster is ready, you can create your first workload cluster.
Preparing the workload cluster configuration
The clusterctl generate cluster command returns a YAML template for creating a workload cluster.
Required configuration for common providers
Depending on the infrastructure provider you are planning to use, some additional prerequisites should be satisfied before configuring a cluster with Cluster API. Instructions are provided for common providers below.
Otherwise, you can look at the clusterctl generate cluster command documentation for details about how to
discover the list of variables required by a cluster templates.
export AWS_REGION=us-east-1
export AWS_SSH_KEY_NAME=default
# Select instance types
export AWS_CONTROL_PLANE_MACHINE_TYPE=t3.large
export AWS_NODE_MACHINE_TYPE=t3.large
See the AWS provider prerequisites document for more details.
# Name of the Azure datacenter location. Change this value to your desired location.
export AZURE_LOCATION="centralus"
# Select VM types.
export AZURE_CONTROL_PLANE_MACHINE_TYPE="Standard_D2s_v3"
export AZURE_NODE_MACHINE_TYPE="Standard_D2s_v3"
A ClusterAPI compatible image must be available in your DigitalOcean account. For instructions on how to build a compatible image see image-builder.
export DO_REGION=nyc1
export DO_SSH_KEY_FINGERPRINT=<your-ssh-key-fingerprint>
export DO_CONTROL_PLANE_MACHINE_TYPE=s-2vcpu-2gb
export DO_CONTROL_PLANE_MACHINE_IMAGE=<your-capi-image-id>
export DO_NODE_MACHINE_TYPE=s-2vcpu-2gb
export DO_NODE_MACHINE_IMAGE==<your-capi-image-id>
The Docker provider does not require additional configurations for cluster templates.
However, if you require special network settings you can set the following environment variables:
# The list of service CIDR, default ["10.128.0.0/12"]
export SERVICE_CIDR=["10.96.0.0/12"]
# The list of pod CIDR, default ["192.168.0.0/16"]
export POD_CIDR=["192.168.0.0/16"]
# The service domain, default "cluster.local"
export SERVICE_DOMAIN="k8s.test"
# Name of the GCP datacenter location. Change this value to your desired location
export GCP_REGION="<GCP_REGION>"
export GCP_PROJECT="<GCP_PROJECT>"
# Make sure to use same kubernetes version here as building the GCE image
export KUBERNETES_VERSION=1.20.9
export GCP_CONTROL_PLANE_MACHINE_TYPE=n1-standard-2
export GCP_NODE_MACHINE_TYPE=n1-standard-2
export GCP_NETWORK_NAME=<GCP_NETWORK_NAME or default>
export CLUSTER_NAME="<CLUSTER_NAME>"
See the GCP provider for more information.
It is required to use an official CAPV machine images for your vSphere VM templates. See uploading CAPV machine images for instructions on how to do this.
# The vCenter server IP or FQDN
export VSPHERE_SERVER="10.0.0.1"
# The vSphere datacenter to deploy the management cluster on
export VSPHERE_DATACENTER="SDDC-Datacenter"
# The vSphere datastore to deploy the management cluster on
export VSPHERE_DATASTORE="vsanDatastore"
# The VM network to deploy the management cluster on
export VSPHERE_NETWORK="VM Network"
# The vSphere resource pool for your VMs
export VSPHERE_RESOURCE_POOL="*/Resources"
# The VM folder for your VMs. Set to "" to use the root vSphere folder
export VSPHERE_FOLDER="vm"
# The VM template to use for your VMs
export VSPHERE_TEMPLATE="ubuntu-1804-kube-v1.17.3"
# The VM template to use for the HAProxy load balancer of the management cluster
export VSPHERE_HAPROXY_TEMPLATE="capv-haproxy-v0.6.0-rc.2"
# The public ssh authorized key on all machines
export VSPHERE_SSH_AUTHORIZED_KEY="ssh-rsa AAAAB3N..."
clusterctl init --infrastructure vsphere
For more information about prerequisites, credentials management, or permissions for vSphere, see the vSphere getting started guide.
A ClusterAPI compatible image must be available in your OpenStack. For instructions on how to build a compatible image see image-builder. Depending on your OpenStack and underlying hypervisor the following options might be of interest:
To see all required OpenStack environment variables execute:
clusterctl generate cluster --infrastructure openstack --list-variables capi-quickstart
The following script can be used to export some of them:
wget https://raw.githubusercontent.com/kubernetes-sigs/cluster-api-provider-openstack/master/templates/env.rc -O /tmp/env.rc
source /tmp/env.rc <path/to/clouds.yaml> <cloud>
Apart from the script, the following OpenStack environment variables are required.
# The list of nameservers for OpenStack Subnet being created.
# Set this value when you need create a new network/subnet while the access through DNS is required.
export OPENSTACK_DNS_NAMESERVERS=<dns nameserver>
# FailureDomain is the failure domain the machine will be created in.
export OPENSTACK_FAILURE_DOMAIN=<availability zone name>
# The flavor reference for the flavor for your server instance.
export OPENSTACK_CONTROL_PLANE_MACHINE_FLAVOR=<flavor>
# The flavor reference for the flavor for your server instance.
export OPENSTACK_NODE_MACHINE_FLAVOR=<flavor>
# The name of the image to use for your server instance. If the RootVolume is specified, this will be ignored and use rootVolume directly.
export OPENSTACK_IMAGE_NAME=<image name>
# The SSH key pair name
export OPENSTACK_SSH_KEY_NAME=<ssh key pair name>
A full configuration reference can be found in configuration.md.
# The URL of the kernel to deploy.
export DEPLOY_KERNEL_URL="http://172.22.0.1:6180/images/ironic-python-agent.kernel"
# The URL of the ramdisk to deploy.
export DEPLOY_RAMDISK_URL="http://172.22.0.1:6180/images/ironic-python-agent.initramfs"
# The URL of the Ironic endpoint.
export IRONIC_URL="http://172.22.0.1:6385/v1/"
# The URL of the Ironic inspector endpoint.
export IRONIC_INSPECTOR_URL="http://172.22.0.1:5050/v1/"
# Do not use a dedicated CA certificate for Ironic API. Any value provided in this variable disables additional CA certificate validation.
# To provide a CA certificate, leave this variable unset. If unset, then IRONIC_CA_CERT_B64 must be set.
export IRONIC_NO_CA_CERT=true
# Disables basic authentication for Ironic API. Any value provided in this variable disables authentication.
# To enable authentication, leave this variable unset. If unset, then IRONIC_USERNAME and IRONIC_PASSWORD must be set.
export IRONIC_NO_BASIC_AUTH=true
# Disables basic authentication for Ironic inspector API. Any value provided in this variable disables authentication.
# To enable authentication, leave this variable unset. If unset, then IRONIC_INSPECTOR_USERNAME and IRONIC_INSPECTOR_PASSWORD must be set.
export IRONIC_INSPECTOR_NO_BASIC_AUTH=true
Please visit the Metal3 getting started guide for more details.
There are a couple of required environment variables that you have to expose in order to get a well tuned and function workload, they are all listed here:
# The project where your cluster will be placed to.
# You have to get out from Packet Portal if you do not have one already.
export PROJECT_ID="5yd4thd-5h35-5hwk-1111-125gjej40930"
# The facility where you want your cluster to be provisioned
export FACILITY="ewr1"
# The operatin system used to provision the device
export NODE_OS="ubuntu_18_04"
# The ssh key name you loaded in Packet Portal
export SSH_KEY="my-ssh"
export POD_CIDR="192.168.0.0/16"
export SERVICE_CIDR="172.26.0.0/16"
export CONTROLPLANE_NODE_TYPE="t1.small"
export WORKER_NODE_TYPE="t1.small"
Generating the cluster configuration
For the purpose of this tutorial, we’ll name our cluster capi-quickstart.
clusterctl generate cluster capi-quickstart \
--kubernetes-version v1.22.0 \
--control-plane-machine-count=3 \
--worker-machine-count=3 \
> capi-quickstart.yaml
clusterctl generate cluster capi-quickstart --flavor development \
--kubernetes-version v1.22.0 \
--control-plane-machine-count=3 \
--worker-machine-count=3 \
> capi-quickstart.yaml
This creates a YAML file named capi-quickstart.yaml with a predefined list of Cluster API objects; Cluster, Machines,
Machine Deployments, etc.
The file can be eventually modified using your editor of choice.
See clusterctl generate cluster for more details.
Apply the workload cluster
When ready, run the following command to apply the cluster manifest.
kubectl apply -f capi-quickstart.yaml
The output is similar to this:
cluster.cluster.x-k8s.io/capi-quickstart created
awscluster.infrastructure.cluster.x-k8s.io/capi-quickstart created
kubeadmcontrolplane.controlplane.cluster.x-k8s.io/capi-quickstart-control-plane created
awsmachinetemplate.infrastructure.cluster.x-k8s.io/capi-quickstart-control-plane created
machinedeployment.cluster.x-k8s.io/capi-quickstart-md-0 created
awsmachinetemplate.infrastructure.cluster.x-k8s.io/capi-quickstart-md-0 created
kubeadmconfigtemplate.bootstrap.cluster.x-k8s.io/capi-quickstart-md-0 created
Accessing the workload cluster
The cluster will now start provisioning. You can check status with:
kubectl get cluster
You can also get an “at glance” view of the cluster and its resources by running:
clusterctl describe cluster capi-quickstart
To verify the first control plane is up:
kubectl get kubeadmcontrolplane
You should see an output is similar to this:
NAME INITIALIZED API SERVER AVAILABLE VERSION REPLICAS READY UPDATED UNAVAILABLE
capi-quickstart-control-plane true v1.21.2 3 3 3
After the first control plane node is up and running, we can retrieve the workload cluster Kubeconfig:
clusterctl get kubeconfig capi-quickstart > capi-quickstart.kubeconfig
Deploy a CNI solution
Calico is used here as an example.
kubectl --kubeconfig=./capi-quickstart.kubeconfig \
apply -f https://docs.projectcalico.org/v3.20/manifests/calico.yaml
After a short while, our nodes should be running and in Ready state,
let’s check the status using kubectl get nodes:
kubectl --kubeconfig=./capi-quickstart.kubeconfig get nodes
Azure does not currently support Calico networking. As a workaround, it is recommended that Azure clusters use the Calico spec below that uses VXLAN.
kubectl --kubeconfig=./capi-quickstart.kubeconfig \
apply -f https://raw.githubusercontent.com/kubernetes-sigs/cluster-api-provider-azure/main/templates/addons/calico.yaml
After a short while, our nodes should be running and in Ready state,
let’s check the status using kubectl get nodes:
kubectl --kubeconfig=./capi-quickstart.kubeconfig get nodes
Clean Up
Delete workload cluster.
kubectl delete cluster capi-quickstart
Delete management cluster
kind delete cluster
Next steps
See the clusterctl documentation for more detail about clusterctl supported actions.
Concepts

Management cluster
A Kubernetes cluster that manages the lifecycle of Workload Clusters. A Management Cluster is also where one or more Infrastructure Providers run, and where resources such as Machines are stored.
Workload cluster
A Kubernetes cluster whose lifecycle is managed by a Management Cluster.
Infrastructure provider
A source of computational resources, such as compute and networking. For example, cloud Infrastructure Providers include AWS, Azure, and Google, and bare metal Infrastructure Providers include VMware, MAAS, and metal3.io.
When there is more than one way to obtain resources from the same Infrastructure Provider (such as AWS offering both EC2 and EKS), each way is referred to as a variant.
Bootstrap provider
The Bootstrap Provider is responsible for:
- Generating the cluster certificates, if not otherwise specified
- Initializing the control plane, and gating the creation of other nodes until it is complete
- Joining control plane and worker nodes to the cluster
Control plane
The control plane is a set of components that serve the Kubernetes API and continuously reconcile desired state using control loops.
-
Machine-based control planes are the most common type. Dedicated machines are provisioned, running static pods for components such as kube-apiserver, kube-controller-manager and kube-scheduler.
-
Pod-based deployments require an external hosting cluster. The control plane components are deployed using standard Deployment and StatefulSet objects and the API is exposed using a Service.
-
External control planes are offered and controlled by some system other than Cluster API, such as GKE, AKS, EKS, or IKS.
As of v1alpha2, Machine-Based is the only control plane type that Cluster API supports.
The default provider uses kubeadm to bootstrap the control plane. As of v1alpha3, it exposes the configuration via the KubeadmControlPlane object. The controller, capi-kubeadm-control-plane-controller-manager, can then create Machine and BootstrapConfig objects based on the requested replicas in the KubeadmControlPlane object.
Custom Resource Definitions (CRDs)
A CustomResourceDefinition is a built-in resource that lets you extend the Kubernetes API. Each CustomResourceDefinition represents a customization of a Kubernetes installation. The Cluster API provides and relies on several CustomResourceDefinitions:
Machine
A “Machine” is the declarative spec for an infrastructure component hosting a Kubernetes Node (for example, a VM). If a new Machine object is created, a provider-specific controller will provision and install a new host to register as a new Node matching the Machine spec. If the Machine’s spec is updated, the controller replaces the host with a new one matching the updated spec. If a Machine object is deleted, its underlying infrastructure and corresponding Node will be deleted by the controller.
Common fields such as Kubernetes version are modeled as fields on the Machine’s spec. Any information that is provider-specific is part of the InfrastructureRef and is not portable between different providers.
Machine Immutability (In-place Upgrade vs. Replace)
From the perspective of Cluster API, all Machines are immutable: once they are created, they are never updated (except for labels, annotations and status), only deleted.
For this reason, MachineDeployments are preferable. MachineDeployments handle changes to machines by replacing them, in the same way core Deployments handle changes to Pod specifications.
MachineDeployment
A MachineDeployment provides declarative updates for Machines and MachineSets.
A MachineDeployment works similarly to a core Kubernetes Deployment. A MachineDeployment reconciles changes to a Machine spec by rolling out changes to 2 MachineSets, the old and the newly updated.
MachineSet
A MachineSet’s purpose is to maintain a stable set of Machines running at any given time.
A MachineSet works similarly to a core Kubernetes ReplicaSet. MachineSets are not meant to be used directly, but are the mechanism MachineDeployments use to reconcile desired state.
MachineHealthCheck
A MachineHealthCheck defines the conditions when a Node should be considered unhealthy.
If the Node matches these unhealthy conditions for a given user-configured time, the MachineHealthCheck initiates remediation of the Node. Remediation of Nodes is performed by deleting the corresponding Machine.
MachineHealthChecks will only remediate Nodes if they are owned by a MachineSet. This ensures that the Kubernetes cluster does not lose capacity, since the MachineSet will create a new Machine to replace the failed Machine.
BootstrapData
BootstrapData contains the Machine or Node role-specific initialization data (usually cloud-init) used by the Infrastructure Provider to bootstrap a Machine into a Node.
Personas
This document describes the personas for the Cluster API 1.0 project as driven from use cases.
We are marking a “proposed priority for project at this time” per use case. This is not intended to say that these use cases aren’t awesome or important. They are intended to indicate where we, as a project, have received a great deal of interest, and as a result where we think we should invest right now to get the most users for our project. If interest grows in other areas, they will be elevated. And, since this is an open source project, if you want to drive feature development for a less-prioritized persona, we absolutely encourage you to join us and do that.
Use-case driven personas
Service Provider: Managed Kubernetes
Managed Kubernetes is an offering in which a provider is automating the lifecycle management of Kubernetes clusters, including full control planes that are available to, and used directly by, the customer.
Proposed priority for project at this time: High
There are several projects from several companies that are building out proposed managed Kubernetes offerings (Project Pacific’s Kubernetes Service from VMware, Microsoft Azure, Google Cloud, Red Hat) and they have all expressed a desire to use Cluster API. This looks like a good place to make sure Cluster API works well, and then expand to other use cases.
Feature matrix
| Is Cluster API exposed to this user? | Yes |
| Are control plane nodes exposed to this user? | Yes |
| How many clusters are being managed via this user? | Many |
| Who is the CAPI admin in this scenario? | Platform Operator |
| Cloud / On-Prem | Both |
| Upgrade strategies desired? | Need to gather data from users |
| How does this user interact with Cluster API? | API |
| ETCD deployment | Need to gather data from users |
| Does this user have a preference for the control plane running on pods vs. vm vs. something else? | Need to gather data from users |
Service Provider: Kubernetes-as-a-Service
Examples of a Kubernetes-as-a-Service provider include services such as Red Hat’s hosted OpenShift, AKS, GKE, and EKS. The cloud services manage the control plane, often giving those cloud resources away “for free,” and the customers spin up and down their own worker nodes.
Proposed priority for project at this time: Medium
Existing Kubernetes as a Service providers, e.g. AKS, GKE have indicated interest in replacing their off-tree automation with Cluster API, however since they already had to build their own automation and it is currently “getting the job done,” switching to Cluster API is not a top priority for them, although it is desirable.
Feature matrix
| Is Cluster API exposed to this user? | Need to gather data from users |
| Are control plane nodes exposed to this user? | No |
| How many clusters are being managed via this user? | Many |
| Who is the CAPI admin in this scenario? | Platform itself (AKS, GKE, etc.) |
| Cloud / On-Prem | Cloud |
| Upgrade strategies desired? | tear down/replace (need confirmation from platforms) |
| How does this user interact with Cluster API? | API |
| ETCD deployment | Need to gather data from users |
| Does this user have a preference for the control plane running on pods vs. vm vs. something else? | Need to gather data from users |
Cluster API Developer
The Cluster API developer is a developer of Cluster API who needs tools and services to make their development experience more productive and pleasant. It’s also important to take a look at the on-boarding experience for new developers to make sure we’re building out a project that other people can more easily submit patches and features to, to encourage inclusivity and welcome new contributors.
Proposed priority for project at this time: Low
We think we’re in a good place right now, and while we welcome contributions to improve the development experience of the project, it should not be the primary product focus of the open source development team to make development better for ourselves.
Feature matrix
| Is Cluster API exposed to this user? | Yes |
| Are control plane nodes exposed to this user? | Yes |
| How many clusters are being managed via this user? | Many |
| Who is the CAPI admin in this scenario? | Platform Operator |
| Cloud / On-Prem | Both |
| Upgrade strategies desired? | Need to gather data from users |
| How does this user interact with Cluster API? | API |
| ETCD deployment | Need to gather data from users |
| Does this user have a preference for the control plane running on pods vs. vm vs. something else? | Need to gather data from users |
Raw API Consumers
Examples of a raw API consumer is a tool like Prow, a customized enterprise platform built on top of Cluster API, or perhaps an advanced “give me a Kubernetes cluster” button exposing some customization that is built using Cluster API.
Proposed priority for project at this time: Low
Feature matrix
| Is Cluster API exposed to this user? | Yes |
| Are control plane nodes exposed to this user? | Yes |
| How many clusters are being managed via this user? | Many |
| Who is the CAPI admin in this scenario? | Platform Operator |
| Cloud / On-Prem | Both |
| Upgrade strategies desired? | Need to gather data from users |
| How does this user interact with Cluster API? | API |
| ETCD deployment | Need to gather data from users |
| Does this user have a preference for the control plane running on pods vs. vm vs. something else? | Need to gather data from users |
Tooling: Provisioners
Examples of this use case, in which a tooling provisioner is using Cluster API to automate behavior, includes tools such as kops and kubicorn.
Proposed priority for project at this time: Low
Maintainers of tools such as kops have indicated interest in using Cluster API, but they have also indicated they do not have much time to take on the work. If this changes, this use case would increase in priority.
Feature matrix
| Is Cluster API exposed to this user? | Need to gather data from tooling maintainers |
| Are control plane nodes exposed to this user? | Yes |
| How many clusters are being managed via this user? | One (per execution) |
| Who is the CAPI admin in this scenario? | Kubernetes Platform Consumer |
| Cloud / On-Prem | Cloud |
| Upgrade strategies desired? | Need to gather data from users |
| How does this user interact with Cluster API? | CLI |
| ETCD deployment | (Stacked or external) AND new |
| Does this user have a preference for the control plane running on pods vs. vm vs. something else? | Need to gather data from users |
Service Provider: End User/Consumer
This user would be an end user or consumer who is given direct access to Cluster API via their service provider to manage Kubernetes clusters. While there are some commercial projects who plan on doing this (Project Pacific, others), they are doing this as a “super user” feature behind the backdrop of a “Managed Kubernetes” offering.
Proposed priority for project at this time: Low
This is a use case we should keep an eye on to see how people use Cluster API directly, but we think the more relevant use case is people building managed offerings on top at this top.
Feature matrix
| Is Cluster API exposed to this user? | Yes |
| Are control plane nodes exposed to this user? | Yes |
| How many clusters are being managed via this user? | Many |
| Who is the CAPI admin in this scenario? | Platform Operator |
| Cloud / On-Prem | Both |
| Upgrade strategies desired? | Need to gather data from users |
| How does this user interact with Cluster API? | API |
| ETCD deployment | Need to gather data from users |
| Does this user have a preference for the control plane running on pods vs. vm vs. something else? | Need to gather data from users |
Cluster Management Tasks
This section provides details for some of the operations that need to be performed when managing clusters.
Certificate Management
This section details some tasks related to certificate management.
Using Custom Certificates
Cluster API expects certificates and keys used for bootstrapping to follow the below convention. CABPK generates new certificates using this convention if they do not already exist.
Each certificate must be stored in a single secret named one of:
| Name | Type | Example |
|---|---|---|
| [cluster name]-ca | CA | openssl req -x509 -subj “/CN=Kubernetes API” -new -newkey rsa:2048 -nodes -keyout tls.key -sha256 -days 3650 -out tls.crt |
| [cluster name]-etcd | CA | openssl req -x509 -subj “/CN=ETCD CA” -new -newkey rsa:2048 -nodes -keyout tls.key -sha256 -days 3650 -out tls.crt |
| [cluster name]-proxy | CA | openssl req -x509 -subj “/CN=Front-End Proxy” -new -newkey rsa:2048 -nodes -keyout tls.key -sha256 -days 3650 -out tls.crt |
| [cluster name]-sa | Key Pair | openssl genrsa -out tls.key 2048 && openssl rsa -in tls.key -pubout -out tls.crt |
Example
apiVersion: v1
kind: Secret
metadata:
name: cluster1-ca
type: kubernetes.io/tls
data:
tls.crt: <base 64 encoded PEM>
tls.key: <base 64 encoded PEM>
Generating a Kubeconfig with your own CA
-
Create a new Certificate Signing Request (CSR) for the
system:mastersKubernetes role, or specify any other role under CN.openssl req -subj "/CN=system:masters" -new -newkey rsa:2048 -nodes -out admin.csr -keyout admin.key -out admin.csr -
Sign the CSR using the [cluster-name]-ca key:
openssl x509 -req -in admin.csr -CA tls.crt -CAkey tls.key -CAcreateserial -out admin.crt -days 5 -sha256 -
Update your kubeconfig with the sign key:
kubectl config set-credentials cluster-admin --client-certificate=admin.crt --client-key=admin.key --embed-certs=true
Cluster API bootstrap provider kubeadm
What is the Cluster API bootstrap provider kubeadm?
Cluster API bootstrap provider Kubeadm (CABPK) is a component responsible for generating a cloud-init script to turn a Machine into a Kubernetes Node. This implementation uses kubeadm for Kubernetes bootstrap.
Resources
How does CABPK work?
CABPK is integrated into cluster-api-manager. Assuming you’ve set of CAPI and the Docker Manager, create a Cluster object and its corresponding DockerCluster
infrastructure object.
kind: DockerCluster
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3
metadata:
name: my-cluster-docker
---
kind: Cluster
apiVersion: cluster.x-k8s.io/v1alpha3
metadata:
name: my-cluster
spec:
infrastructureRef:
kind: DockerCluster
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3
name: my-cluster-docker
Now you can start creating machines by defining a Machine, its corresponding DockerMachine object, and
the KubeadmConfig bootstrap object.
kind: KubeadmConfig
apiVersion: bootstrap.cluster.x-k8s.io/v1alpha3
metadata:
name: my-control-plane1-config
spec:
initConfiguration:
nodeRegistration:
kubeletExtraArgs:
eviction-hard: nodefs.available<0%,nodefs.inodesFree<0%,imagefs.available<0%
clusterConfiguration:
controllerManager:
extraArgs:
enable-hostpath-provisioner: "true"
---
kind: DockerMachine
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3
metadata:
name: my-control-plane1-docker
---
kind: Machine
apiVersion: cluster.x-k8s.io/v1alpha3
metadata:
name: my-control-plane1
labels:
cluster.x-k8s.io/cluster-name: my-cluster
cluster.x-k8s.io/control-plane: "true"
set: controlplane
spec:
bootstrap:
configRef:
kind: KubeadmConfig
apiVersion: bootstrap.cluster.x-k8s.io/v1alpha3
name: my-control-plane1-config
infrastructureRef:
kind: DockerMachine
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3
name: my-control-plane1-docker
version: "v1.19.1"
CABPK’s main responsibility is to convert a KubeadmConfig bootstrap object into a cloud-init script that is
going to turn a Machine into a Kubernetes Node using kubeadm.
The cloud-init script will be saved into a secret KubeadmConfig.Status.DataSecretName and then the infrastructure provider
(CAPD in this example) will pick up this value and proceed with the machine creation and the actual bootstrap.
KubeadmConfig objects
The KubeadmConfig object allows full control of Kubeadm init/join operations by exposing raw InitConfiguration,
ClusterConfiguration and JoinConfiguration objects.
CABPK will fill in some values if they are left empty with sensible defaults:
KubeadmConfig field | Default |
|---|---|
clusterConfiguration.KubernetesVersion | Machine.Spec.Version[1] |
clusterConfiguration.clusterName | Cluster.metadata.name |
clusterConfiguration.controlPlaneEndpoint | Cluster.status.apiEndpoints[0] |
clusterConfiguration.networking.dnsDomain | Cluster.spec.clusterNetwork.serviceDomain |
clusterConfiguration.networking.serviceSubnet | Cluster.spec.clusterNetwork.service.cidrBlocks[0] |
clusterConfiguration.networking.podSubnet | Cluster.spec.clusterNetwork.pods.cidrBlocks[0] |
joinConfiguration.discovery | a short lived BootstrapToken generated by CABPK |
IMPORTANT! overriding above defaults could lead to broken Clusters.
[1] if both clusterConfiguration.KubernetesVersion and Machine.Spec.Version are empty, the latest Kubernetes
version will be installed (as defined by the default kubeadm behavior).
Examples
Valid combinations of configuration objects are:
- for KCP,
InitConfigurationandClusterConfigurationfor the first control plane node;JoinConfigurationfor additional control plane nodes - for machine deployments,
JoinConfigurationfor worker nodes
Bootstrap control plane node:
kind: KubeadmConfig
apiVersion: bootstrap.cluster.x-k8s.io/v1alpha3
metadata:
name: my-control-plane1-config
spec:
initConfiguration:
nodeRegistration:
kubeletExtraArgs:
eviction-hard: nodefs.available<0%,nodefs.inodesFree<0%,imagefs.available<0%
clusterConfiguration:
controllerManager:
extraArgs:
enable-hostpath-provisioner: "true"
Additional control plane nodes:
kind: KubeadmConfig
apiVersion: bootstrap.cluster.x-k8s.io/v1alpha3
metadata:
name: my-control-plane2-config
spec:
joinConfiguration:
nodeRegistration:
kubeletExtraArgs:
eviction-hard: nodefs.available<0%,nodefs.inodesFree<0%,imagefs.available<0%
controlPlane: {}
worker nodes:
kind: KubeadmConfig
apiVersion: bootstrap.cluster.x-k8s.io/v1alpha3
metadata:
name: my-worker1-config
spec:
joinConfiguration:
nodeRegistration:
kubeletExtraArgs:
eviction-hard: nodefs.available<0%,nodefs.inodesFree<0%,imagefs.available<0%
Bootstrap Orchestration
CABPK supports multiple control plane machines initing at the same time. The generation of cloud-init scripts of different machines is orchestrated in order to ensure a cluster bootstrap process that will be compliant with the correct Kubeadm init/join sequence. More in detail:
- cloud-config-data generation starts only after
Cluster.Status.InfrastructureReadyflag is set totrue. - at this stage, cloud-config-data will be generated for the first control plane machine only, keeping on hold additional control plane machines existing in the cluster, if any (kubeadm init).
- after the
ControlPlaneInitializedconditions on the cluster object is set to true, the cloud-config-data for all the other machines are generated (kubeadm join/join —control-plane).
Certificate Management
The user can choose two approaches for certificate management:
- provide required certificate authorities (CAs) to use for
kubeadm init/kubeadm join --control-plane; such CAs should be provided as aSecretsobjects in the management cluster. - let KCP to generate the necessary
Secretsobjects with a self-signed certificate authority for kubeadm
See here for more info about certificate management with kubeadm.
Additional Features
The KubeadmConfig object supports customizing the content of the config-data. The following examples illustrate how to specify these options. They should be adapted to fit your environment and use case.
-
KubeadmConfig.Filesspecifies additional files to be created on the machine, either with content inline or by referencing a secret.files: - contentFrom: secret: key: node-cloud.json name: ${CLUSTER_NAME}-md-0-cloud-json owner: root:root path: /etc/kubernetes/cloud.json permissions: "0644" - path: /etc/kubernetes/cloud.json owner: "root:root" permissions: "0644" content: | { "cloud": "CustomCloud" } -
KubeadmConfig.PreKubeadmCommandsspecifies a list of commands to be executed beforekubeadm init/joinpreKubeadmCommands: - hostname "{{ ds.meta_data.hostname }}" - echo "{{ ds.meta_data.hostname }}" >/etc/hostname -
KubeadmConfig.PostKubeadmCommandssame as above, but afterkubeadm init/joinpostKubeadmCommands: - echo "success" >/var/log/my-custom-file.log -
KubeadmConfig.Usersspecifies a list of users to be created on the machineusers: - name: capiuser sshAuthorizedKeys: - '${SSH_AUTHORIZED_KEY}' sudo: ALL=(ALL) NOPASSWD:ALL -
KubeadmConfig.NTPspecifies NTP settings for the machinentp: servers: - IP_ADDRESS enabled: true -
KubeadmConfig.DiskSetupspecifies options for the creation of partition tables and file systems on devices.diskSetup: filesystems: - device: /dev/disk/azure/scsi1/lun0 extraOpts: - -E - lazy_itable_init=1,lazy_journal_init=1 filesystem: ext4 label: etcd_disk - device: ephemeral0.1 filesystem: ext4 label: ephemeral0 replaceFS: ntfs partitions: - device: /dev/disk/azure/scsi1/lun0 layout: true overwrite: false tableType: gpt -
KubeadmConfig.Mountsspecifies a list of mount points to be setup.mounts: - - LABEL=etcd_disk - /var/lib/etcddisk -
KubeadmConfig.Verbosityspecifies thekubeadmlog level verbosityverbosity: 10 -
KubeadmConfig.UseExperimentalRetryJoinreplaces a basic kubeadm command with a shell script with retries for joins. This will add about 40KB to userdata.useExperimentalRetryJoin: true
For more information on cloud-init options, see cloud config examples.
Upgrading management and workload clusters
Considerations
Supported versions of Kubernetes
If you are upgrading the version of Kubernetes for a cluster managed by Cluster API, check that the running version of Cluster API on the Management Cluster supports the target Kubernetes version.
You may need to upgrade the version of Cluster API in order to support the target Kubernetes version.
In addition, you must always upgrade between Kubernetes minor versions in sequence, e.g. if you need to upgrade from Kubernetes v1.17 to v1.19, you must first upgrade to v1.18.
Images
For kubeadm based clusters, infrastructure providers require a “machine image” containing pre-installed, matching
versions of kubeadm and kubelet, ensure that relevant infrastructure machine templates reference the appropriate
image for the Kubernetes version.
Upgrading using Cluster API
The high level steps to fully upgrading a cluster are to first upgrade the control plane and then upgrade the worker machines.
Upgrading the control plane machines
How to upgrade the underlying machine image
To upgrade the control plane machines underlying machine images, the MachineTemplate resource referenced by the
KubeadmControlPlane must be changed. Since MachineTemplate resources are immutable, the recommended approach is to
- Copy the existing
MachineTemplate. - Modify the values that need changing, such as instance type or image ID.
- Create the new
MachineTemplateon the management cluster. - Modify the existing
KubeadmControlPlaneresource to reference the newMachineTemplateresource in theinfrastructureReffield.
The next step will trigger a rolling update of the control plane using the new values found in the new MachineTemplate.
How to upgrade the Kubernetes control plane version
To upgrade the Kubernetes control plane version make a modification to the KubeadmControlPlane resource’s Spec.Version field. This will trigger a rolling upgrade of the control plane and, depending on the provider, also upgrade the underlying machine image.
Some infrastructure providers, such as AWS, require
that if a specific machine image is specified, it has to match the Kubernetes version specified in the
KubeadmControlPlane spec. In order to only trigger a single upgrade, the new MachineTemplate should be created first
and then both the Version and InfrastructureTemplate should be modified in a single transaction.
How to schedule a machine rollout
A KubeadmControlPlane resource has a field RolloutAfter that can be set to a timestamp
(RFC-3339) after which a rollout should be triggered regardless of whether there were any changes
to the KubeadmControlPlane.Spec or not. This would roll out replacement control plane nodes
which can be useful e.g. to perform certificate rotation, reflect changes to machine templates,
move to new machines, etc.
Note that this field can only be used for triggering a rollout, not for delaying one. Specifically,
a rollout can also happen before the time specified in RolloutAfter if any changes are made to
the spec before that time.
To do the same for machines managed by a MachineDeployment it’s enough to make an arbitrary
change to its Spec.Template, one common approach is to run:
clusterctl alpha rollout restart machinedeployment/my-md-0
This will modify the template by setting an cluster.x-k8s.io/restartedAt annotation which will
trigger a rollout.
Upgrading machines managed by a MachineDeployment
Upgrades are not limited to just the control plane. This section is not related to Kubeadm control plane specifically, but is the final step in fully upgrading a Cluster API managed cluster.
It is recommended to manage machines with one or more MachineDeployments. MachineDeployments will
transparently manage MachineSets and Machines to allow for a seamless scaling experience. A modification to the
MachineDeployments spec will begin a rolling update of the machines. Follow
these instructions for changing the
template for an existing MachineDeployment.
MachineDeployments support different strategies for rolling out changes to Machines:
- RollingUpdate
Changes are rolled out by honouring MaxUnavailable and MaxSurge values.
Only values allowed are of type Int or Strings with an integer and percentage symbol e.g “5%”.
- OnDelete
Changes are rolled out driven by the user or any entity deleting the old Machines. Only when a Machine is fully deleted a new one will come up.
For a more in-depth look at how MachineDeployments manage scaling events, take a look at the MachineDeployment
controller documentation and the MachineSet controller
documentation.
Upgrading Cluster API components
When to upgrade
In general, it’s recommended to upgrade to the latest version of Cluster API to take advantage of bug fixes, new features and improvements.
Considerations
If moving between different API versions, there may be additional tasks that you need to complete. See below for instructions moving between v1alpha3 and v1alpha4.
Ensure that the version of Cluster API is compatible with the Kubernetes version of the management cluster.
Upgrading to newer versions of 0.4.x
Use clusterctl to upgrade between versions of Cluster API 0.4.x.
Upgrading from Cluster API v1alpha3 (0.3.x) to Cluster API v1alpha4 (0.4.x)
For detailed information about the changes from v1alpha3 to v1alpha4, please refer to the Cluster API v1alpha3 compared to v1alpha4 section.
Use clusterctl to upgrade from Cluster API v0.3.x to Cluster API 0.4.x.
You should now be able to manage your resources using the v1alpha4 version of the Cluster API components.
Configure a MachineHealthCheck
Prerequisites
Before attempting to configure a MachineHealthCheck, you should have a working management cluster with at least one MachineDeployment or MachineSet deployed.
What is a MachineHealthCheck?
A MachineHealthCheck is a resource within the Cluster API which allows users to define conditions under which Machines within a Cluster should be considered unhealthy. A MachineHealthCheck is defined on a management cluster and scoped to a particular workload cluster.
When defining a MachineHealthCheck, users specify a timeout for each of the conditions that they define to check on the Machine’s Node. If any of these conditions are met for the duration of the timeout, the Machine will be remediated. By default, the action of remediating a Machine should trigger a new Machine to be created to replace the failed one, but providers are allowed to plug in more sophisticated external remediation solutions.
Creating a MachineHealthCheck
Use the following example as a basis for creating a MachineHealthCheck for worker nodes:
apiVersion: cluster.x-k8s.io/v1alpha3
kind: MachineHealthCheck
metadata:
name: capi-quickstart-node-unhealthy-5m
spec:
# clusterName is required to associate this MachineHealthCheck with a particular cluster
clusterName: capi-quickstart
# (Optional) maxUnhealthy prevents further remediation if the cluster is already partially unhealthy
maxUnhealthy: 40%
# (Optional) nodeStartupTimeout determines how long a MachineHealthCheck should wait for
# a Node to join the cluster, before considering a Machine unhealthy.
# Defaults to 10 minutes if not specified.
# Set to 0 to disable the node startup timeout.
# Disabling this timeout will prevent a Machine from being considered unhealthy when
# the Node it created has not yet registered with the cluster. This can be useful when
# Nodes take a long time to start up or when you only want condition based checks for
# Machine health.
nodeStartupTimeout: 10m
# selector is used to determine which Machines should be health checked
selector:
matchLabels:
nodepool: nodepool-0
# Conditions to check on Nodes for matched Machines, if any condition is matched for the duration of its timeout, the Machine is considered unhealthy
unhealthyConditions:
- type: Ready
status: Unknown
timeout: 300s
- type: Ready
status: "False"
timeout: 300s
Use this example as the basis for defining a MachineHealthCheck for control plane nodes managed via the KubeadmControlPlane:
apiVersion: cluster.x-k8s.io/v1alpha3
kind: MachineHealthCheck
metadata:
name: capi-quickstart-kcp-unhealthy-5m
spec:
clusterName: capi-quickstart
maxUnhealthy: 100%
selector:
matchLabels:
cluster.x-k8s.io/control-plane: ""
unhealthyConditions:
- type: Ready
status: Unknown
timeout: 300s
- type: Ready
status: "False"
timeout: 300s
Remediation Short-Circuiting
To ensure that MachineHealthChecks only remediate Machines when the cluster is healthy,
short-circuiting is implemented to prevent further remediation via the maxUnhealthy and unhealthyRange fields within the MachineHealthCheck spec.
Max Unhealthy
If the user defines a value for the maxUnhealthy field (either an absolute number or a percentage of the total Machines checked by this MachineHealthCheck),
before remediating any Machines, the MachineHealthCheck will compare the value of maxUnhealthy with the number of Machines it has determined to be unhealthy.
If the number of unhealthy Machines exceeds the limit set by maxUnhealthy, remediation will not be performed.
With an Absolute Value
If maxUnhealthy is set to 2:
- If 2 or fewer nodes are unhealthy, remediation will be performed
- If 3 or more nodes are unhealthy, remediation will not be performed
These values are independent of how many Machines are being checked by the MachineHealthCheck.
With Percentages
If maxUnhealthy is set to 40% and there are 25 Machines being checked:
- If 10 or fewer nodes are unhealthy, remediation will be performed
- If 11 or more nodes are unhealthy, remediation will not be performed
If maxUnhealthy is set to 40% and there are 6 Machines being checked:
- If 2 or fewer nodes are unhealthy, remediation will be performed
- If 3 or more nodes are unhealthy, remediation will not be performed
Note, when the percentage is not a whole number, the allowed number is rounded down.
Unhealthy Range
If the user defines a value for the unhealthyRange field (bracketed values that specify a start and an end value), before remediating any Machines,
the MachineHealthCheck will check if the number of Machines it has determined to be unhealthy is within the range specified by unhealthyRange.
If it is not within the range set by unhealthyRange, remediation will not be performed.
With a range of values
If unhealthyRange is set to [3-5] and there are 10 Machines being checked:
- If 2 or fewer nodes are unhealthy, remediation will not be performed.
- If 5 or more nodes are unhealthy, remediation will not be performed.
- In all other cases, remediation will be performed.
Note, the above example had 10 machines as sample set. But, this would work the same way for any other number. This is useful for dynamically scaling clusters where the number of machines keep changing frequently.
Skipping Remediation
There are scenarios where remediation for a machine may be undesirable (eg. during cluster migration using clustrctl move). For such cases, MachineHealthCheck provides 2 mechanisms to skip machines for remediation.
Implicit skipping when the resource is paused (using cluster.x-k8s.io/paused annotation):
- When a cluster is paused, none of the machines in that cluster are considered for remediation.
- When a machine is paused, only that machine is not considered for remediation.
- A cluster or a machine is usually paused automatically by Cluster API when it detects a migration.
Explicit skipping using cluster.x-k8s.io/skip-remediation annotation:
- Users can also skip any machine for remediation by setting the
cluster.x-k8s.io/skip-remediationfor that machine.
Limitations and Caveats of a MachineHealthCheck
Before deploying a MachineHealthCheck, please familiarise yourself with the following limitations and caveats:
- Only Machines owned by a MachineSet or a KubeadmControlPlane can be remediated by a MachineHealthCheck (since a MachineDeployment uses a MachineSet, then this includes Machines that are part of a MachineDeployment)
- Machines managed by a KubeadmControlPlane are remediated according to the delete-and-recreate guidelines described in the KubeadmControlPlane proposal
- If the Node for a Machine is removed from the cluster, a MachineHealthCheck will consider this Machine unhealthy and remediate it immediately
- If no Node joins the cluster for a Machine after the
NodeStartupTimeout, the Machine will be remediated - If a Machine fails for any reason (if the FailureReason is set), the Machine will be remediated immediately
Kubeadm control plane
Using the Kubeadm control plane type to manage a control plane provides several ways to upgrade control plane machines.
Kubeconfig management
KCP will generate and manage the admin Kubeconfig for clusters. The client certificate for the admin user is created with a valid lifespan of a year, and will be automatically regenerated when the cluster is reconciled and has less than 6 months of validity remaining.
Upgrades
See the section on upgrading clusters.
Using Kubeadm Control Plane when upgrading from Cluster API v1alpha2 (0.2.x)
See the section on Adopting existing machines into KubeadmControlPlane management
Running workloads on control plane machines
We don’t suggest running workloads on control planes, and highly encourage avoiding it unless absolutely necessary.
However, in the case the user wants to run non-control plane workloads on control plane machines they are ultimately responsible for ensuring the proper functioning of those workloads, given that KCP is not aware of the specific requirements for each type of workload (e.g. preserving quorum, shutdown procedures etc.).
In order to do so, the user could leverage on the same assumption that applies to all the Cluster API Machines:
- The Kubernetes node hosted on the Machine will be cordoned & drained before removal (with well known exceptions like full Cluster deletion).
- The Machine will respect PreDrainDeleteHook and PreTerminateDeleteHook. see the Machine Deletion Phase Hooks proposal for additional details.
Updating Machine Infrastructure and Bootstrap Templates
Updating Infrastructure Machine Templates
Several different components of Cluster API leverage infrastructure machine templates,
including KubeadmControlPlane, MachineDeployment, and MachineSet. These
MachineTemplate resources should be immutable, unless the infrastructure provider
documentation indicates otherwise for certain fields (see below for more details).
The correct process for modifying an infrastructure machine template is as follows:
- Duplicate an existing template.
Users can use
kubectl get <MachineTemplateType> <name> -o yaml > file.yamlto retrieve a template configuration from a running cluster to serve as a starting point. - Update the desired fields. Fields that might need to be modified could include the SSH key, the AWS instance type, or the Azure VM size. Refer to the provider-specific documentation for more details on the specific fields that each provider requires or accepts.
- Give the newly-modified template a new name by modifying the
metadata.namefield (or by usingmetadata.generateName). - Create the new infrastructure machine template on the API server using
kubectl. (If the template was initially created using the command in step 1, be sure to clear out any extraneous metadata, including theresourceVersionfield, before trying to send it to the API server.)
Once the new infrastructure machine template has been persisted, users may modify
the object that was referencing the infrastructure machine template. For example,
to modify the infrastructure machine template for the KubeadmControlPlane object,
users would modify the spec.infrastructureTemplate.name field. For a MachineDeployment
or MachineSet, users would need to modify the spec.template.spec.infrastructureRef.name
field. In all cases, the name field should be updated to point to the newly-modified
infrastructure machine template. This will trigger a rolling update. (This same process
is described in the documentation for upgrading the underlying machine image for
KubeadmControlPlane in the “How to upgrade the underlying
machine image” section.)
Some infrastructure providers may, at their discretion, choose to support in-place modifications of certain infrastructure machine template fields. This may be useful if an infrastructure provider is able to make changes to running instances/machines, such as updating allocated memory or CPU capacity. In such cases, however, Cluster API will not trigger a rolling update.
Updating Bootstrap Templates
Several different components of Cluster API leverage bootstrap templates,
including MachineDeployment, and MachineSet. When used in MachineDeployment or
MachineSet changes to those templates do not trigger rollouts of already existing Machines.
New Machines are created based on the current version of the bootstrap template.
The correct process for modifying a bootstrap template is as follows:
- Duplicate an existing template.
Users can use
kubectl get <BootstrapTemplateType> <name> -o yaml > file.yamlto retrieve a template configuration from a running cluster to serve as a starting point. - Update the desired fields.
- Give the newly-modified template a new name by modifying the
metadata.namefield (or by usingmetadata.generateName). - Create the new bootstrap template on the API server using
kubectl. (If the template was initially created using the command in step 1, be sure to clear out any extraneous metadata, including theresourceVersionfield, before trying to send it to the API server.)
Once the new bootstrap template has been persisted, users may modify
the object that was referencing the bootstrap template. For example,
to modify the bootstrap template for the MachineDeployment object,
users would modify the spec.template.spec.bootstrap.configRef.name field.
The name field should be updated to point to the newly-modified
bootstrap template. This will trigger a rolling update.
Using the Cluster Autoscaler
Cluster Autoscaler is a tool that automatically adjusts the size of the Kubernetes cluster based on the utilization of Pods and Nodes in your cluster. For more general information about the Cluster Autoscaler, please see the project documentation.
The following instructions are a reproduction of the Cluster API provider specific documentation from the Autoscaler project documentation.
Cluster Autoscaler on Cluster API
The cluster autoscaler on Cluster API uses the cluster-api project to manage the provisioning and de-provisioning of nodes within a Kubernetes cluster.
Kubernetes Version
The cluster-api provider requires Kubernetes v1.16 or greater to run the v1alpha3 version of the API.
Starting the Autoscaler
To enable the Cluster API provider, you must first specify it in the command line arguments to the cluster autoscaler binary. For example:
cluster-autoscaler --cloud-provider=clusterapi
Please note, this example only shows the cloud provider options, you will
most likely need other command line flags. For more information you can invoke
cluster-autoscaler --help to see a full list of options.
Configuring node group auto discovery
If you do not configure node group auto discovery, cluster autoscaler will attempt to match nodes against any scalable resources found in any namespace and belonging to any Cluster.
Limiting cluster autoscaler to only match against resources in the blue namespace
--node-group-auto-discovery=clusterapi:namespace=blue
Limiting cluster autoscaler to only match against resources belonging to Cluster test1
--node-group-auto-discovery=clusterapi:clusterName=test1
Limiting cluster autoscaler to only match against resources matching the provided labels
--node-group-auto-discovery=clusterapi:color=green,shape=square
These can be mixed and matched in any combination, for example to only match resources in the staging namespace, belonging to the purple cluster, with the label owner=jim:
--node-group-auto-discovery=clusterapi:namespace=staging,clusterName=purple,owner=jim
Connecting cluster-autoscaler to Cluster API management and workload Clusters
You will also need to provide the path to the kubeconfig(s) for the management
and workload cluster you wish cluster-autoscaler to run against. To specify the
kubeconfig path for the workload cluster to monitor, use the --kubeconfig
option and supply the path to the kubeconfig. If the --kubeconfig option is
not specified, cluster-autoscaler will attempt to use an in-cluster configuration.
To specify the kubeconfig path for the management cluster to monitor, use the
--cloud-config option and supply the path to the kubeconfig. If the
--cloud-config option is not specified it will fall back to using the kubeconfig
that was provided with the --kubeconfig option.
Autoscaler running in a joined cluster using service account credentials
+-----------------+
| mgmt / workload |
| --------------- |
| autoscaler |
+-----------------+
Use in-cluster config for both management and workload cluster:
cluster-autoscaler --cloud-provider=clusterapi
Autoscaler running in workload cluster using service account credentials, with separate management cluster
+--------+ +------------+
| mgmt | | workload |
| | cloud-config | ---------- |
| |<-------------+ autoscaler |
+--------+ +------------+
Use in-cluster config for workload cluster, specify kubeconfig for management cluster:
cluster-autoscaler --cloud-provider=clusterapi \
--cloud-config=/mnt/kubeconfig
Autoscaler running in management cluster using service account credentials, with separate workload cluster
+------------+ +----------+
| mgmt | | workload |
| ---------- | kubeconfig | |
| autoscaler +------------>| |
+------------+ +----------+
Use in-cluster config for management cluster, specify kubeconfig for workload cluster:
cluster-autoscaler --cloud-provider=clusterapi \
--kubeconfig=/mnt/kubeconfig \
--clusterapi-cloud-config-authoritative
Autoscaler running anywhere, with separate kubeconfigs for management and workload clusters
+--------+ +------------+ +----------+
| mgmt | | ? | | workload |
| | cloud-config | ---------- | kubeconfig | |
| |<--------------+ autoscaler +------------>| |
+--------+ +------------+ +----------+
Use separate kubeconfigs for both management and workload cluster:
cluster-autoscaler --cloud-provider=clusterapi \
--kubeconfig=/mnt/workload.kubeconfig \
--cloud-config=/mnt/management.kubeconfig
Autoscaler running anywhere, with a common kubeconfig for management and workload clusters
+---------------+ +------------+
| mgmt/workload | | ? |
| | kubeconfig | ---------- |
| |<------------+ autoscaler |
+---------------+ +------------+
Use a single provided kubeconfig for both management and workload cluster:
cluster-autoscaler --cloud-provider=clusterapi \
--kubeconfig=/mnt/workload.kubeconfig
Enabling Autoscaling
To enable the automatic scaling of components in your cluster-api managed cloud there are a few annotations you need to provide. These annotations must be applied to either MachineSet or MachineDeployment resources depending on the type of cluster-api mechanism that you are using.
There are two annotations that control how a cluster resource should be scaled:
-
cluster.x-k8s.io/cluster-api-autoscaler-node-group-min-size- This specifies the minimum number of nodes for the associated resource group. The autoscaler will not scale the group below this number. Please note that currently the cluster-api provider will not scale down to zero nodes. -
cluster.x-k8s.io/cluster-api-autoscaler-node-group-max-size- This specifies the maximum number of nodes for the associated resource group. The autoscaler will not scale the group above this number.
The autoscaler will monitor any MachineSet or MachineDeployment containing
both of these annotations.
Specifying a Custom Resource Group
By default all Kubernetes resources consumed by the Cluster API provider will
use the group cluster.x-k8s.io, with a dynamically acquired version. In
some situations, such as testing or prototyping, you may wish to change this
group variable. For these situations you may use the environment variable
CAPI_GROUP to change the group that the provider will use.
Please note that setting the CAPI_GROUP environment variable will also cause the
annotations for minimum and maximum size to change.
This behavior will also affect the machine annotation on nodes, the machine deletion annotation,
and the cluster name label. For example, if CAPI_GROUP=test.k8s.io
then the minimum size annotation key will be test.k8s.io/cluster-api-autoscaler-node-group-min-size,
the machine annotation on nodes will be test.8s.io/machine, the machine deletion
annotation will be test.k8s.io/delete-machine, and the cluster name label will be
test.k8s.io/cluster-name.
Specifying a Custom Resource Version
When determining the group version for the Cluster API types, by default the autoscaler
will look for the latest version of the group. For example, if MachineDeployments
exist in the cluster.x-k8s.io group at versions v1alpha1 and v1beta1, the
autoscaler will choose v1beta1.
In some cases it may be desirable to specify which version of the API the cluster autoscaler should use. This can be useful in debugging scenarios, or in situations where you have deployed multiple API versions and wish to ensure that the autoscaler uses a specific version.
Setting the CAPI_VERSION environment variable will instruct the autoscaler to use
the version specified. This works in a similar fashion as the API group environment
variable with the exception that there is no default value. When this variable is not
set, the autoscaler will use the behavior described above.
Sample manifest
A sample manifest that will create a deployment running the autoscaler is
available. It can be deployed by passing it through envsubst, providing
these environment variables to set the namespace to deploy into as well as the image and tag to use:
export AUTOSCALER_NS=kube-system
export AUTOSCALER_IMAGE=us.gcr.io/k8s-artifacts-prod/autoscaling/cluster-autoscaler:v1.20.0
envsubst < examples/deployment.yaml | kubectl apply -f-
A note on permissions
The cluster-autoscaler-management role for accessing cluster api scalable resources is scoped to ClusterRole.
This may not be ideal for all environments (eg. Multi tenant environments).
In such cases, it is recommended to scope it to a Role mapped to a specific namespace.
Experimental Features
Cluster API now ships with a new experimental package that lives under the exp/ directory. This is a
temporary location for features which will be moved to their permanent locations after graduation. Users can experiment with these features by enabling them using feature gates.
Enabling Experimental Features for Management Clusters Started with clusterctl
Users can enable/disable features by setting OS environment variables before running clusterctl init, e.g.:
export EXP_CLUSTER_RESOURCE_SET=true
clusterctl init --infrastructure vsphere
As an alternative to environment variables, it is also possible to set variables in the clusterctl config file located at $HOME/.cluster-api/clusterctl.yaml, e.g.:
# Values for environment variable substitution
EXP_CLUSTER_RESOURCE_SET: "true"
In case a variable is defined in both the config file and as an OS environment variable, the environment variable takes precedence. For more information on how to set variables for clusterctl, see clusterctl Configuration File
Some features like MachinePools may require infrastructure providers to implement a separate CRD that handles the infrastructure side of the feature too.
For such a feature to work, infrastructure providers should also enable their controllers if it is implemented as a feature. If it is not implemented as a feature, no additional step is necessary.
As an example, Cluster API Provider Azure (CAPZ) has support for MachinePool through the infrastructure type AzureMachinePool.
Enabling Experimental Features for e2e Tests
One way is to set experimental variables on the clusterctl config file. For CAPI, these configs are under ./test/e2e/config/... such as docker-ci.yaml:
variables:
EXP_CLUSTER_RESOURCE_SET: "true"
EXP_MACHINE_POOL: "true"
Another way is to set them as environmental variables before running e2e tests.
Enabling Experimental Features on Tilt
On development environments started with Tilt, features can be enabled by setting the feature variables in kustomize_substitutions, e.g.:
{
"enable_providers": ["kubeadm-bootstrap","kubeadm-control-plane"],
"allowed_contexts": ["kind-kind"],
"default_registry": "gcr.io/cluster-api-provider",
"provider_repos": [],
"kustomize_substitutions": {
"EXP_CLUSTER_RESOURCE_SET": "true",
"EXP_MACHINE_POOL": "true"
}
}
For more details on setting up a development environment with tilt, see Developing Cluster API with Tilt
Enabling Experimental Features on Existing Management Clusters
To enable/disable features on existing management clusters, users can modify CAPI controller manager deployment which will restart all controllers with requested features.
# kubectl edit -n capi-system deployment.apps/capi-controller-manager
// Enable/disable available feautures by modifying Args below.
Args:
--leader-elect
--feature-gates=MachinePool=true,ClusterResourceSet=true
Similarly, to validate if a particular feature is enabled, see cluster-api-provider deployment arguments by:
# kubectl describe -n capi-system deployment.apps/capi-controller-manager
Active Experimental Features
Warning: Experimental features are unreliable, i.e., some may one day be promoted to the main repository, or they may be modified arbitrarily or even disappear altogether. In short, they are not subject to any compatibility or deprecation promise.
Experimental Feature: MachinePool (alpha)
The MachinePool feature provides a way to manage a set of machines by defining a common configuration, number of desired machine replicas etc. similar to MachineDeployment,
except MachineSet controllers are responsible for the lifecycle management of the machines for MachineDeployment, whereas in MachinePools,
each infrastructure provider has a specific solution for orchestrating these Machines.
Feature gate name: MachinePool
Variable name to enable/disable the feature gate: EXP_MACHINE_POOL
Infrastructure providers can support this feature by implementing their specific MachinePool such as AzureMachinePool.
More details on MachinePool can be found at:
MachinePool CAEP
For developer docs on the MachinePool controller, see here.
Experimental Feature: ClusterResourceSet (alpha)
The ClusterResourceSet feature is introduced to provide a way to automatically apply a set of resources (such as CNI/CSI) defined by users to matching newly-created/existing clusters.
Feature gate name: ClusterResourceSet
Variable name to enable/disable the feature gate: EXP_CLUSTER_RESOURCE_SET
More details on ClusterResourceSet and an example to test it can be found at:
ClusterResourceSet CAEP
Overview of clusterctl
The clusterctl CLI tool handles the lifecycle of a Cluster API management cluster.
The clusterctl command line interface is specifically designed for providing a simple “day 1 experience” and a
quick start with Cluster API. It automates fetching the YAML files defining provider components and installing them.
Additionally it encodes a set of best practices in managing providers, that helps the user in avoiding mis-configurations or in managing day 2 operations such as upgrades.
-
use
clusterctl initto install Cluster API providers -
use
clusterctl upgradeto upgrade Cluster API providers -
use
clusterctl deleteto delete Cluster API providers -
use
clusterctl generate clusterto spec out workload clusters -
use
clusterctl generate yamlto process yaml -
use
clusterctl get kubeconfigto get the kubeconfig of an existing workload cluster. using clusterctl’s internal yaml processor. -
use
clusterctl moveto migrate objects defining a workload clusters (e.g. Cluster, Machines) from a management cluster to another management cluster -
use
clusterctl alpha rolloutto rollout Cluster API resources such as MachineDeployments. Note that this is currently an alpha level feature.
clusterctl Commands
clusterctl initclusterctl generate clusterclusterctl generate yamlclusterctl get kubeconfigclusterctl describe clusterclusterctl moveclusterctl upgradeclusterctl deleteclusterctl completionclusterctl alpha rolloutclusterctl config cluster(deprecated)
clusterctl init
The clusterctl init command installs the Cluster API components and transforms the Kubernetes cluster
into a management cluster.
This document provides more detail on how clusterctl init works and on the supported options for customizing your
management cluster.
Defining the management cluster
The clusterctl init command accepts in input a list of providers to install.
Automatically installed providers
The clusterctl init command automatically adds the cluster-api core provider, the kubeadm bootstrap provider, and
the kubeadm control-plane provider to the list of providers to install. This allows users to use a concise command syntax for initializing a management cluster.
For example, to get a fully operational management cluster with the aws infrastructure provider, the cluster-api core provider, the kubeadm bootstrap, and the kubeadm control-plane provider, use the command:
clusterctl init --infrastructure aws
Provider version
The clusterctl init command by default installs the latest version available
for each selected provider.
Target namespace
The clusterctl init command by default installs each provider in the default target namespace defined by each provider, e.g. capi-system for the Cluster API core provider.
See the provider documentation for more details.
Provider repositories
To access provider specific information, such as the components YAML to be used for installing a provider,
clusterctl init accesses the provider repositories, that are well-known places where the release assets for
a provider are published.
See clusterctl configuration for more info about provider repository configurations.
Variable substitution
Providers can use variables in the components YAML published in the provider’s repository.
During clusterctl init, those variables are replaced with environment variables or with variables read from the
clusterctl configuration.
Additional information
When installing a provider, the clusterctl init command executes a set of steps to simplify
the lifecycle management of the provider’s components.
- All the provider’s components are labeled, so they can be easily identified in subsequent moments of the provider’s lifecycle, e.g. upgrades.
labels:
- clusterctl.cluster.x-k8s.io: ""
- cluster.x-k8s.io/provider: "<provider-name>"
- An additional
Providerobject is created in the target namespace where the provider is installed. This object keeps track of the provider version, and other useful information for the inventory of the providers currently installed in the management cluster.
Cert-manager
Cluster API providers require a cert-manager version supporting the cert-manager.io/v1 API to be installed in the cluster.
While doing init, clusterctl checks if there is a version of cert-manager already installed. If not, clusterctl will install a default version (currently cert-manager v1.5.3). See clusterctl configuration for available options to customize this operation.
clusterctl generate cluster
The clusterctl generate cluster command returns a YAML template for creating a workload cluster.
For example
clusterctl generate cluster my-cluster --kubernetes-version v1.16.3 --control-plane-machine-count=3 --worker-machine-count=3 > my-cluster.yaml
Generates a YAML file named my-cluster.yaml with a predefined list of Cluster API objects; Cluster, Machines,
Machine Deployments, etc. to be deployed in the current namespace (in case, use the --target-namespace flag to
specify a different target namespace).
Then, the file can be modified using your editor of choice; when ready, run the following command to apply the cluster manifest.
kubectl apply -f my-cluster.yaml
Selecting the infrastructure provider to use
The clusterctl generate cluster command uses smart defaults in order to simplify the user experience; in the example above,
it detects that there is only an aws infrastructure provider in the current management cluster and so it automatically
selects a cluster template from the aws provider’s repository.
In case there is more than one infrastructure provider, the following syntax can be used to select which infrastructure provider to use for the workload cluster:
clusterctl generate cluster my-cluster --kubernetes-version v1.16.3 \
--infrastructure aws > my-cluster.yaml
or
clusterctl generate cluster my-cluster --kubernetes-version v1.16.3 \
--infrastructure aws:v0.4.1 > my-cluster.yaml
Flavors
The infrastructure provider authors can provide different types of cluster templates, or flavors; use the --flavor flag
to specify which flavor to use; e.g.
clusterctl generate cluster my-cluster --kubernetes-version v1.16.3 \
--flavor high-availability > my-cluster.yaml
Please refer to the providers documentation for more info about available flavors.
Alternative source for cluster templates
clusterctl uses the provider’s repository as a primary source for cluster templates; the following alternative sources for cluster templates can be used as well:
ConfigMaps
Use the --from-config-map flag to read cluster templates stored in a Kubernetes ConfigMap; e.g.
clusterctl generate cluster my-cluster --kubernetes-version v1.16.3 \
--from-config-map my-templates > my-cluster.yaml
Also following flags are available --from-config-map-namespace (defaults to current namespace) and --from-config-map-key
(defaults to template).
GitHub or local file system folder
Use the --from flag to read cluster templates stored in a GitHub repository or in a local file system folder; e.g.
clusterctl generate cluster my-cluster --kubernetes-version v1.16.3 \
--from https://github.com/my-org/my-repository/blob/master/my-template.yaml > my-cluster.yaml
or
clusterctl generate cluster my-cluster --kubernetes-version v1.16.3 \
--from ~/my-template.yaml > my-cluster.yaml
Variables
If the selected cluster template expects some environment variables, the user should ensure those variables are set in advance.
E.g. if the AWS_CREDENTIALS variable is expected for a cluster template targeting the aws infrastructure, you
should ensure the corresponding environment variable to be set before executing clusterctl generate cluster.
Please refer to the providers documentation for more info about the required variables or use the
clusterctl generate cluster --list-variables flag to get a list of variables names required by a cluster template.
The clusterctl configuration file can be used as alternative to environment variables.
clusterctl generate yaml
The clusterctl generate yaml command processes yaml using clusterctl’s yaml
processor.
The intent of this command is to allow users who may have specific templates to leverage clusterctl’s yaml processor for variable substitution. For example, this command can be leveraged in local and CI scripts or for development purposes.
clusterctl ships with a simple yaml processor that performs variable substitution that takes into account default values. Under the hood, clusterctl’s yaml processor uses drone/envsubst to replace variables and uses the defaults if necessary.
Variable values are either sourced from the clusterctl config file or from environment variables.
Current usage of the command is as follows:
# Generates a configuration file with variable values using a template from a
# specific URL.
clusterctl generate yaml --from https://github.com/foo-org/foo-repository/blob/master/cluster-template.yaml
# Generates a configuration file with variable values using
# a template stored locally.
clusterctl generate yaml --from ~/workspace/cluster-template.yaml
# Prints list of variables used in the local template
clusterctl generate yaml --from ~/workspace/cluster-template.yaml --list-variables
# Prints list of variables from template passed in via stdin
cat ~/workspace/cluster-template.yaml | clusterctl generate yaml --from - --list-variables
# Default behavior for this sub-command is to read from stdin.
# Generate configuration from stdin
cat ~/workspace/cluster-template.yaml | clusterctl generate yaml
clusterctl get kubeconfig
This command prints the kubeconfig of an existing workload cluster into stdout. This functionality is available in clusterctl v0.3.9 or newer.
Examples
Get the kubeconfig of a workload cluster named foo.
clusterctl get kubeconfig foo
Get the kubeconfig of a workload cluster named foo in the namespace bar
clusterctl get kubeconfig foo --namespace bar
Get the kubeconfig of a workload cluster named foo using a specific context bar
clusterctl get kubeconfig foo --kubeconfig-context bar
clusterctl describe cluster
The clusterctl describe cluster command provides an “at a glance” view of a Cluster API cluster designed
to help the user in quickly understanding if there are problems and where.
For example clusterctl describe cluster capi-quickstart will provide an output similar to:

The “at a glance” view is based on the idea that clusterctl should avoid overloading the user with information, but instead surface problems, if any.
In practice, if you look at the ControlPlane node, you might notice that the underlying machines
are grouped together, because all of them have the same state (Ready equal to True), so it is not
necessary to repeat the same information three times.
If this is not the case, and machines have different states, the visualization is going to use different lines:

You might also notice that the visualization does not represent the infrastructure machine or the bootstrap object linked to a machine, unless their state differs from the machine’s state.
Customizing the visualization
By default the visualization generated by clusterctl describe cluster hides details for the sake
of simplicity and shortness. However, if required, the user can ask for showing all the detail:
By using the --disable-grouping flag, the user can force the visualization to show all the machines
on separated lines, no matter if they have the same state or not:

By using the --disable-no-echo flag, the user can force the visualization to show infrastructure machines and
bootstrap objects linked to machines, no matter if they have the same state or not:

It is also possible to force the visualization to show all the conditions for an object (instead of showing
only the ready condition). e.g. with --show-conditions KubeadmControlPlane you get:

Please note that this option is flexible, and you can pass a comma separated list of kind or kind/name for
which the command should show all the object’s conditions (use ‘all’ to show conditions for everything).
clusterctl move
The clusterctl move command allows to move the Cluster API objects defining workload clusters, like e.g. Cluster, Machines,
MachineDeployments, etc. from one management cluster to another management cluster.
You can use:
clusterctl move --to-kubeconfig="path-to-target-kubeconfig.yaml"
To move the Cluster API objects existing in the current namespace of the source management cluster; in case if you want
to move the Cluster API objects defined in another namespace, you can use the --namespace flag.
Pivot
Pivoting is a process for moving the provider components and declared Cluster API resources from a source management cluster to a target management cluster.
This can now be achieved with the following procedure:
- Use
clusterctl initto install the provider components into the target management cluster - Use
clusterctl moveto move the cluster-api resources from a Source Management cluster to a Target Management cluster
Bootstrap & Pivot
The pivot process can be bounded with the creation of a temporary bootstrap cluster used to provision a target Management cluster.
This can now be achieved with the following procedure:
- Create a temporary bootstrap cluster, e.g. using Kind or Minikube
- Use
clusterctl initto install the provider components - Use
clusterctl generate cluster ... | kubectl apply -f -to provision a target management cluster - Wait for the target management cluster to be up and running
- Get the kubeconfig for the new target management cluster
- Use
clusterctl initwith the new cluster’s kubeconfig to install the provider components - Use
clusterctl moveto move the Cluster API resources from the bootstrap cluster to the target management cluster - Delete the bootstrap cluster
Note: It’s required to have at least one worker node to schedule Cluster API workloads (i.e. controllers). A cluster with a single control plane node won’t be sufficient due to the
NoScheduletaint. If a worker node isn’t available,clusterctl initwill timeout.
Dry run
With --dry-run option you can dry-run the move action by only printing logs without taking any actual actions. Use log level verbosity -v to see different levels of information.
clusterctl upgrade
The clusterctl upgrade command can be used to upgrade the version of the Cluster API providers (CRDs, controllers)
installed into a management cluster.
upgrade plan
The clusterctl upgrade plan command can be used to identify possible targets for upgrades.
clusterctl upgrade plan
Produces an output similar to this:
Checking cert-manager version...
Cert-Manager will be upgraded from "v0.11.0" to "v1.5.3"
Checking new release availability...
Management group: capi-system/cluster-api, latest release available for the v1alpha4 API Version of Cluster API (contract):
NAME NAMESPACE TYPE CURRENT VERSION NEXT VERSION
bootstrap-kubeadm capi-kubeadm-bootstrap-system BootstrapProvider v0.4.0 v0.4.1
control-plane-kubeadm capi-kubeadm-control-plane-system ControlPlaneProvider v0.4.0 v0.4.1
cluster-api capi-system CoreProvider v0.4.0 v0.4.1
infrastructure-azure capz-system InfrastructureProvider v0.4.0 v0.4.1
You can now apply the upgrade by executing the following command:
clusterctl upgrade apply --contract v1alpha4
The output contains the latest release available for each API Version of Cluster API (contract) available at the moment.
upgrade apply
After choosing the desired option for the upgrade, you can run the following command to upgrade all the providers in the management cluster. This upgrades all the providers to the latest stable releases.
clusterctl upgrade apply --contract v1alpha4
The upgrade process is composed by three steps:
- Check the cert-manager version, and if necessary, upgrade it.
- Delete the current version of the provider components, while preserving the namespace where the provider components are hosted and the provider’s CRDs.
- Install the new version of the provider components.
Please note that clusterctl does not upgrade Cluster API objects (Clusters, MachineDeployments, Machine etc.); upgrading such objects are the responsibility of the provider’s controllers.
clusterctl delete
The clusterctl delete command deletes the provider components from the management cluster.
The operation is designed to prevent accidental deletion of user created objects. For example:
clusterctl delete --infrastructure aws
This command deletes the AWS infrastructure provider components, while preserving the namespace where the provider components are hosted and the provider’s CRDs.
If you want to delete all the providers in a single operation , you can use the --all flag.
clusterctl delete --all
clusterctl completion
The clusterctl completion command outputs shell completion code for the
specified shell (bash or zsh). The shell code must be evaluated to provide
interactive completion of clusterctl commands.
Bash
To install bash-completion on macOS, use Homebrew:
brew install bash-completion
Once installed, bash_completion must be evaluated. This can be done by adding
the following line to the ~/.bash_profile.
[[ -r "$(brew --prefix)/etc/profile.d/bash_completion.sh" ]] && . "$(brew --prefix)/etc/profile.d/bash_completion.sh"
If bash-completion is not installed on Linux, please install the ‘bash-completion’ package via your distribution’s package manager.
You now have to ensure that the clusterctl completion script gets sourced in all your shell sessions. There are multiple ways to achieve this:
- Source the completion script in your
~/.bash_profilefile:source <(clusterctl completion bash) - Add the completion script to the /usr/local/etc/bash_completion.d directory:
clusterctl completion bash >/usr/local/etc/bash_completion.d/clusterctl
Zsh
The clusterctl completion script for Zsh can be generated with the command
clusterctl completion zsh.
If shell completion is not already enabled in your environment you will need to enable it. You can execute the following once:
echo "autoload -U compinit; compinit" >> ~/.zshrc
To load completions for each session, execute once:
clusterctl completion zsh > "${fpath[1]}/_clusterctl"
You will need to start a new shell for this setup to take effect.
clusterctl Configuration File
The clusterctl config file is located at $HOME/.cluster-api/clusterctl.yaml.
It can be used to:
- Customize the list of providers and provider repositories.
- Provide configuration values to be used for variable substitution when installing providers or creating clusters.
- Define image overrides for air-gapped environments.
Provider repositories
The clusterctl CLI is designed to work with providers implementing the clusterctl Provider Contract.
Each provider is expected to define a provider repository, a well-known place where release assets are published.
By default, clusterctl ships with providers sponsored by SIG Cluster
Lifecycle. Use clusterctl config repositories to get a list of supported
providers and their repository configuration.
Users can customize the list of available providers using the clusterctl configuration file, as shown in the following example:
providers:
# add a custom provider
- name: "my-infra-provider"
url: "https://github.com/myorg/myrepo/releases/latest/infrastructure-components.yaml"
type: "InfrastructureProvider"
# override a pre-defined provider
- name: "cluster-api"
url: "https://github.com/myorg/myforkofclusterapi/releases/latest/core-components.yaml"
type: "CoreProvider"
See provider contract for instructions about how to set up a provider repository.
Variables
When installing a provider clusterctl reads a YAML file that is published in the provider repository. While executing
this operation, clusterctl can substitute certain variables with the ones provided by the user.
The same mechanism also applies when clusterctl reads the cluster templates YAML published in the repository, e.g.
when injecting the Kubernetes version to use, or the number of worker machines to create.
The user can provide values using OS environment variables, but it is also possible to add
variables in the clusterctl config file:
# Values for environment variable substitution
AWS_B64ENCODED_CREDENTIALS: XXXXXXXX
In case a variable is defined both in the config file and as an OS environment variable, the environment variable takes precedence.
Cert-Manager configuration
While doing init, clusterctl checks if there is a version of cert-manager already installed. If not, clusterctl will install a default version.
By default, cert-manager will be fetched from https://github.com/jetstack/cert-manager/releases; however, if the user
wants to use a different repository, it is possible to use the following configuration:
cert-manager:
url: "/Users/foo/.cluster-api/dev-repository/cert-manager/latest/cert-manager.yaml"
Similarly, it is possible to override the default version installed by clusterctl by configuring:
cert-manager:
...
version: "v1.1.1"
For situations when resources are limited or the network is slow, the cert-manager wait time to be running can be customized by adding a field to the clusterctl config file, for example:
```yaml
cert-manager:
...
timeout: 15m
The value string is a possibly signed sequence of decimal numbers, each with optional fraction and a unit suffix, such as “300ms”, “-1.5h” or “2h45m”. Valid time units are “ns”, “us” (or “µs”), “ms”, “s”, “m”, “h”.
If no value is specified, or the format is invalid, the default value of 10 minutes will be used.
Please note that the configuration above will be considered also when doing clusterctl upgrade plan or clusterctl upgrade plan.
Overrides Layer
clusterctl uses an overrides layer to read in injected provider components,
cluster templates and metadata. By default, it reads the files from
$HOME/.cluster-api/overrides.
The directory structure under the overrides directory should follow the
template:
<providerType-providerName>/<version>/<fileName>
For example,
├── bootstrap-kubeadm
│ └── v0.3.0
│ └── bootstrap-components.yaml
├── cluster-api
│ └── v0.3.0
│ └── core-components.yaml
├── control-plane-kubeadm
│ └── v0.3.0
│ └── control-plane-components.yaml
└── infrastructure-aws
└── v0.5.0
├── cluster-template-dev.yaml
└── infrastructure-components.yaml
For developers who want to generate the overrides layer, see Build artifacts locally.
Once these overrides are specified, clusterctl will use them instead of
getting the values from the default or specified providers.
One example usage of the overrides layer is that it allows you to deploy clusters with custom templates that may not be available from the official provider repositories. For example, you can now do:
clusterctl generate cluster mycluster --flavor dev --infrastructure aws:v0.5.0 -v5
The -v5 provides verbose logging which will confirm the usage of the
override file.
Using Override="cluster-template-dev.yaml" Provider="infrastructure-aws" Version="v0.5.0"
Another example, if you would like to deploy a custom version of CAPA, you can
make changes to infrastructure-components.yaml in the overrides folder and
run,
clusterctl init --infrastructure aws:v0.5.0 -v5
...
Using Override="infrastructure-components.yaml" Provider="infrastructure-aws" Version="v0.5.0"
...
If you prefer to have the overrides directory at a different location (e.g.
/Users/foobar/workspace/dev-releases) you can specify the overrides
directory in the clusterctl config file as
overridesFolder: /Users/foobar/workspace/dev-releases
Image overrides
When working in air-gapped environments, it’s necessary to alter the manifests to be installed in order to pull
images from a local/custom image repository instead of public ones (e.g. gcr.io, or quay.io).
The clusterctl configuration file can be used to instruct clusterctl to override images automatically.
This can be achieved by adding an images configuration entry as shown in the example:
images:
all:
repository: myorg.io/local-repo
Please note that the image override feature allows for more fine-grained configuration, allowing to set image overrides for specific components, for example:
images:
all:
repository: myorg.io/local-repo
cert-manager:
tag: v1.5.3
In this example we are overriding the image repository for all the components and the image tag for all the images in the cert-manager component.
If required to alter only a specific image you can use:
images:
all:
repository: myorg.io/local-repo
cert-manager/cert-manager-cainjector:
tag: v1.5.3
Debugging/Logging
To have more verbose logs you can use the -v flag when running the clusterctl and set the level of the logging verbose with a positive integer number, ie. -v 3.
If you do not want to use the flag every time you issue a command you can set the environment variable CLUSTERCTL_LOG_LEVEL or set the variable in the clusterctl config file located by default at $HOME/.cluster-api/clusterctl.yaml.
clusterctl Provider Contract
The clusterctl command is designed to work with all the providers compliant with the following rules.
Provider Repositories
Each provider MUST define a provider repository, that is a well-known place where the release assets for a provider are published.
The provider repository MUST contain the following files:
- The metadata YAML
- The components YAML
Additionally, the provider repository SHOULD contain the following files:
- Workload cluster templates
Creating a provider repository on GitHub
You can use a GitHub release to package your provider artifacts for other people to use.
A GitHub release can be used as a provider repository if:
- The release tag is a valid semantic version number
- The components YAML, the metadata YAML and eventually the workload cluster templates are include into the release assets.
See the GitHub help for more information about how to create a release.
Creating a local provider repository
clusterctl supports reading from a repository defined on the local file system.
A local repository can be defined by creating a <provider-label> folder with a <version> sub-folder for each hosted release;
the sub-folder name MUST be a valid semantic version number. e.g.
~/local-repository/infrastructure-aws/v0.5.2
Each version sub-folder MUST contain the corresponding components YAML, the metadata YAML and eventually the workload cluster templates.
Metadata YAML
The provider is required to generate a metadata YAML file and publish it to the provider’s repository.
The metadata YAML file documents the release series of each provider and maps each release series to an API Version of Cluster API (contract).
For example, for Cluster API:
apiVersion: clusterctl.cluster.x-k8s.io/v1alpha3
kind: Metadata
releaseSeries:
- major: 0
minor: 3
contract: v1alpha3
- major: 0
minor: 2
contract: v1alpha2
Components YAML
The provider is required to generate a components YAML file and publish it to the provider’s repository. This file is a single YAML with all the components required for installing the provider itself (CRDs, Controller, RBAC etc.).
The following rules apply:
Naming conventions
It is strongly recommended that:
- Core providers release a file called
core-components.yaml - Infrastructure providers release a file called
infrastructure-components.yaml - Bootstrap providers release a file called
bootstrap-components.yaml - Control plane providers release a file called
control-plane-components.yaml
Target namespace
The instance components should contain one Namespace object, which will be used as the default target namespace when creating the provider components.
All the objects in the components YAML MUST belong to the target namespace, with the exception of objects that are not namespaced, like ClusterRoles/ClusterRoleBinding and CRD objects.
Controllers & Watching namespace
Each provider is expected to deploy controllers using a Deployment.
While defining the Deployment Spec, the container that executes the controller binary MUST be called manager.
The manager MUST support a --namespace flag for specifying the namespace where the controller
will look for objects to reconcile; however, clusterctl will always install providers watching for all namespaces
(--namespace=""); for more details see support for multiple instances
for more context.
Variables
The components YAML can contain environment variables matching the format ${VAR}; it is highly
recommended to prefix the variable name with the provider name e.g. ${AWS_CREDENTIALS}
clusterctl uses the library drone/envsubst to perform
variable substitution.
# If `VAR` is not set or empty, the default value is used. This is true for
# all the following formats.
${VAR:=default}
${VAR=default}
${VAR:-default}
Other functions such as substring replacement are also supported by the library. See drone/envsubst for more information.
Additionally, each provider should create user facing documentation with the list of required variables and with all the additional notes that are required to assist the user in defining the value for each variable.
Labels
The components YAML components should be labeled with
cluster.x-k8s.io/provider and the name of the provider. This will enable an
easier transition from kubectl apply to clusterctl.
As a reference you can consider the labels applied to the following providers.
| Provider Name | Label |
|---|---|
| CAPI | cluster.x-k8s.io/provider=cluster-api |
| CABPK | cluster.x-k8s.io/provider=bootstrap-kubeadm |
| CACPK | cluster.x-k8s.io/provider=control-plane-kubeadm |
| CACPN | cluster.x-k8s.io/provider=control-plane-nested |
| CAPA | cluster.x-k8s.io/provider=infrastructure-aws |
| CAPIBM | cluster.x-k8s.io/provider=infrastructure-ibmcloud |
| CAPV | cluster.x-k8s.io/provider=infrastructure-vsphere |
| CAPD | cluster.x-k8s.io/provider=infrastructure-docker |
| CAPM3 | cluster.x-k8s.io/provider=infrastructure-metal3 |
| CAPN | cluster.x-k8s.io/provider=infrastructure-nested |
| CAPP | cluster.x-k8s.io/provider=infrastructure-packet |
| CAPZ | cluster.x-k8s.io/provider=infrastructure-azure |
| CAPO | cluster.x-k8s.io/provider=infrastructure-openstack |
| CAPDO | cluster.x-k8s.io/provider=infrastructure-digitalocean |
Workload cluster templates
An infrastructure provider could publish a cluster templates file to be used by clusterctl generate cluster.
This is single YAML with all the objects required to create a new workload cluster.
The following rules apply:
Naming conventions
Cluster templates MUST be stored in the same folder as the component YAML and follow this naming convention:
- The default cluster template should be named
cluster-template.yaml. - Additional cluster template should be named
cluster-template-{flavor}.yaml. e.gcluster-template-prod.yaml
{flavor} is the name the user can pass to the clusterctl generate cluster --flavor flag to identify the specific template to use.
Each provider SHOULD create user facing documentation with the list of available cluster templates.
Target namespace
The cluster template YAML MUST assume the target namespace already exists.
All the objects in the cluster template YAML MUST be deployed in the same namespace.
Variables
The cluster templates YAML can also contain environment variables (as can the components YAML).
Additionally, each provider should create user facing documentation with the list of required variables and with all the additional notes that are required to assist the user in defining the value for each variable.
Common variables
The clusterctl generate cluster command allows user to set a small set of common variables via CLI flags or command arguments.
Templates writers should use the common variables to ensure consistency across providers and a simpler user experience
(if compared to the usage of OS environment variables or the clusterctl config file).
| CLI flag | Variable name | Note |
|---|---|---|
--target-namespace | ${NAMESPACE} | The namespace where the workload cluster should be deployed |
--kubernetes-version | ${KUBERNETES_VERSION} | The Kubernetes version to use for the workload cluster |
--controlplane-machine-count | ${CONTROL_PLANE_MACHINE_COUNT} | The number of control plane machines to be added to the workload cluster |
--worker-machine-count | ${WORKER_MACHINE_COUNT} | The number of worker machines to be added to the workload cluster |
Additionally, the value of the command argument to clusterctl generate cluster <cluster-name> (<cluster-name> in this case), will
be applied to every occurrence of the ${ CLUSTER_NAME } variable.
OwnerReferences chain
Each provider is responsible to ensure that all the providers resources (like e.g. VSphereCluster, VSphereMachine, VSphereVM etc.
for the vsphere provider) MUST have a Metadata.OwnerReferences entry that links directly or indirectly to a Cluster object.
Please note that all the provider specific resources that are referenced by the Cluster API core objects will get the OwnerReference
set by the Cluster API core controllers, e.g.:
- The Cluster controller ensures that all the objects referenced in
Cluster.Spec.InfrastructureRefget anOwnerReferencethat links directly to the correspondingCluster. - The Machine controller ensures that all the objects referenced in
Machine.Spec.InfrastructureRefget anOwnerReferencethat links to the correspondingMachine, and theMachineis linked to theClusterthrough its ownOwnerReferencechain.
That means that, practically speaking, provider implementers are responsible for ensuring that the OwnerReferences
are set only for objects that are not directly referenced by Cluster API core objects, e.g.:
- All the
VSphereVMinstances should get anOwnerReferencethat links to the correspondingVSphereMachine, and theVSphereMachineis linked to theClusterthrough its ownOwnerReferencechain.
Additional notes
Components YAML transformations
Provider authors should be aware of the following transformations that clusterctl applies during component installation:
- Variable substitution;
- Enforcement of target namespace:
- The name of the namespace object is set;
- The namespace field of all the objects is set (with exception of cluster wide objects like e.g. ClusterRoles);
- All components are labeled;
Cluster template transformations
Provider authors should be aware of the following transformations that clusterctl applies during components installation:
- Variable substitution;
- Enforcement of target namespace:
- The namespace field of all the objects are set;
Links to external objects
The clusterctl command requires that both the components YAML and the cluster templates contain all the required
objects.
If, for any reason, the provider authors/YAML designers decide not to comply with this recommendation and e.g. to
- implement links to external objects from a component YAML (e.g. secrets, aggregated ClusterRoles NOT included in the component YAML)
- implement link to external objects from a cluster template (e.g. secrets, configMaps NOT included in the cluster template)
The provider authors/YAML designers should be aware that it is their responsibility to ensure the proper
functioning of clusterctl when using non-compliant component YAML or cluster templates.
Move
Provider authors should be aware that clusterctl move command implements a discovery mechanism that considers:
- All the Kind defined in one of the CRDs installed by clusterctl using
clusterctl init(identified via theclusterctl.cluster.x-k8s.io label); For each CRD, discovery collects:- All the objects from the namespace being moved only if the CRD scope is
Namespaced. - All the objects if the CRD scope is
Cluster.
- All the objects from the namespace being moved only if the CRD scope is
- All the
ConfigMapobjects from the namespace being moved. - All the
Secretobjects from the namespace being moved and from the namespaces where infrastructure providers are installed.
After completing discovery, clusterctl move moves to the target cluster only the objects discovered in the previous phase
that are compliant with one of the following rules:
- The object is directly or indirectly linked to a
Clusterobject (linked through theOwnerReferencechain). - The object is a secret containing a user provided certificate (linked to a
Clusterobject via a naming convention). - The object is directly or indirectly linked to a
ClusterResourceSetobject (through theOwnerReferencechain). - The object is directly or indirectly linked to another object with the
clusterctl.cluster.x-k8s.io/move-hierarchylabel, e.g. the infrastructure Provider ClusterIdentity objects (linked through theOwnerReferencechain). - The object hase the
clusterctl.cluster.x-k8s.io/movelabel or theclusterctl.cluster.x-k8s.io/move-hierarchylabel, e.g. the CPI config secret.
Note. clusterctl.cluster.x-k8s.io/move and clusterctl.cluster.x-k8s.io/move-hierarchy labels could be applied
to single objects or at the CRD level (the label applies to all the objects).
Please note that during move:
- Namespaced objects, if not existing in the target cluster, are created.
- Namespaced objects, if already existing in the target cluster, are updated.
- Namespaced objects are removed from the source cluster.
- Global objects, if not existing in the target cluster, are created.
- Global objects, if already existing in the target cluster, are not updated.
- Global objects are not removed from the source cluster.
- Namespaced objects which are part of an owner chain that starts with a global object (e.g. a secret containing credentials for an infrastructure Provider ClusterIdentity) are treated as Global objects.
If moving some of excluded object is required, the provider authors should create documentation describing the exact move sequence to be executed by the user.
Additionally, provider authors should be aware that clusterctl move assumes all the provider’s Controllers respect the
Cluster.Spec.Paused field introduced in the v1alpha3 Cluster API specification.
clusterctl for Developers
This document describes how to use clusterctl during the development workflow.
Prerequisites
- A Cluster API development setup (go, git, kind v0.9 or newer, Docker v19.03 or newer etc.)
- A local clone of the Cluster API GitHub repository
- A local clone of the GitHub repositories for the providers you want to install
Build clusterctl
From the root of the local copy of Cluster API, you can build the clusterctl binary by running:
make clusterctl
The output of the build is saved in the bin/ folder; In order to use it you have to specify
the full path, create an alias or copy it into a folder under your $PATH.
Use local artifacts
Clusterctl by default uses artifacts published in the providers repositories; during the development workflow you may want to use artifacts from your local workstation.
There are two options to do so:
- Use the overrides layer, when you want to override a single published artifact with a local one.
- Create a local repository, when you want to avoid using published artifacts and use the local ones instead.
If you want to create a local artifact, follow these instructions:
Build artifacts locally
In order to build artifacts for the CAPI core provider, the kubeadm bootstrap provider and the kubeadm control plane provider:
make docker-build REGISTRY=gcr.io/k8s-staging-cluster-api
make generate-manifests REGISTRY=gcr.io/k8s-staging-cluster-api PULL_POLICY=IfNotPresent
In order to build docker provider artifacts
make -C test/infrastructure/docker docker-build REGISTRY=gcr.io/k8s-staging-cluster-api
make -C test/infrastructure/docker generate-manifests REGISTRY=gcr.io/k8s-staging-cluster-api PULL_POLICY=IfNotPresent
Create a clusterctl-settings.json file
Next, create a clusterctl-settings.json file and place it in your local copy
of Cluster API. This file will be used by create-local-repository.py. Here is an example:
{
"providers": ["cluster-api","bootstrap-kubeadm","control-plane-kubeadm", "infrastructure-aws", "infrastructure-docker"],
"provider_repos": ["../cluster-api-provider-aws"]
}
providers (Array[]String, default=[]): A list of the providers to enable. See available providers for more details.
provider_repos (Array[]String, default=[]): A list of paths to all the providers you want to use. Each provider must have
a clusterctl-settings.json file describing how to build the provider assets.
Create the local repository
Run the create-local-repository hack from the root of the local copy of Cluster API:
cmd/clusterctl/hack/create-local-repository.py
The script reads from the source folders for the providers you want to install, builds the providers’ assets,
and places them in a local repository folder located under $HOME/.cluster-api/dev-repository/.
Additionally, the command output provides you the clusterctl init command with all the necessary flags.
The output should be similar to:
clusterctl local overrides generated from local repositories for the cluster-api, bootstrap-kubeadm, control-plane-kubeadm, infrastructure-docker, infrastructure-aws providers.
in order to use them, please run:
clusterctl init \
--core cluster-api:v0.3.8 \
--bootstrap kubeadm:v0.3.8 \
--control-plane kubeadm:v0.3.8 \
--infrastructure aws:v0.5.0 \
--infrastructure docker:v0.3.8 \
--config ~/.cluster-api/dev-repository/config.yaml
As you might notice, the command is using the $HOME/.cluster-api/dev-repository/config.yaml config file,
containing all the required setting to make clusterctl use the local repository.
Available providers
The following providers are currently defined in the script:
cluster-apibootstrap-kubeadmcontrol-plane-kubeadminfrastructure-docker
More providers can be added by editing the clusterctl-settings.json in your local copy of Cluster API;
please note that each provider_repo should have its own clusterctl-settings.json describing how to build the provider assets, e.g.
{
"name": "infrastructure-aws",
"config": {
"componentsFile": "infrastructure-components.yaml",
"nextVersion": "v0.5.0",
}
}
Create a kind management cluster
kind can provide a Kubernetes cluster to be used as a management cluster. See Install and/or configure a kubernetes cluster for more information.
Before running clusterctl init, you must ensure all the required images are available in the kind cluster.
This is always the case for images published in some image repository like docker hub or gcr.io, but it can’t be
the case for images built locally; in this case, you can use kind load to move the images built locally. e.g
kind load docker-image gcr.io/k8s-staging-cluster-api/cluster-api-controller-amd64:dev
kind load docker-image gcr.io/k8s-staging-cluster-api/kubeadm-bootstrap-controller-amd64:dev
kind load docker-image gcr.io/k8s-staging-cluster-api/kubeadm-control-plane-controller-amd64:dev
kind load docker-image gcr.io/k8s-staging-cluster-api/capd-manager-amd64:dev
to make the controller images available for the kubelet in the management cluster.
When the kind cluster is ready and all the required images are in place, run the clusterctl init command generated by the create-local-repository.py script.
Optionally, you may want to check if the components are running properly. The exact components are dependent on which providers you have initialized. Below is an example output with the docker provider being installed.
kubectl get deploy -A | grep "cap\|cert"
capd-system capd-controller-manager 1/1 1 1 25m
capi-kubeadm-bootstrap-system capi-kubeadm-bootstrap-controller-manager 1/1 1 1 25m
capi-kubeadm-control-plane-system capi-kubeadm-control-plane-controller-manager 1/1 1 1 25m
capi-system capi-controller-manager 1/1 1 1 25m
cert-manager cert-manager 1/1 1 1 27m
cert-manager cert-manager-cainjector 1/1 1 1 27m
cert-manager cert-manager-webhook 1/1 1 1 27m
Additional Notes for the Docker Provider
Select the appropriate kubernetes version
When selecting the --kubernetes-version, ensure that the kindest/node
image is available.
For example, on docker hub there is no
image for version v1.21.2, therefore creating a CAPD workload cluster with
--kubernetes-version=v1.21.2 will fail. See issue 3795 for more details.
Get the kubeconfig for the workload cluster
The command for getting the kubeconfig file for connecting to a workload cluster is the following:
clusterctl get kubeconfig capi-quickstart > capi-quickstart.kubeconfig
Fix kubeconfig (when using docker on MacOS)
When using docker on MacOS, you will need to do a couple of additional steps to get the correct kubeconfig for a workload cluster created with the Docker provider:
# Point the kubeconfig to the exposed port of the load balancer, rather than the inaccessible container IP.
sed -i -e "s/server:.*/server: https:\/\/$(docker port capi-quickstart-lb 6443/tcp | sed "s/0.0.0.0/127.0.0.1/")/g" ./capi-quickstart.kubeconfig
# Ignore the CA, because it is not signed for 127.0.0.1
sed -i -e "s/certificate-authority-data:.*/insecure-skip-tls-verify: true/g" ./capi-quickstart.kubeconfig
Developer Guide
Pieces of Cluster API
Cluster API is made up of many components, all of which need to be running for correct operation. For example, if you wanted to use Cluster API with AWS, you’d need to install both the cluster-api manager and the aws manager.
Cluster API includes a built-in provisioner, Docker, that’s suitable for using for testing and development. This guide will walk you through getting that daemon, known as CAPD, up and running.
Other providers may have additional steps you need to follow to get up and running.
Prerequisites
Docker
Iterating on the cluster API involves repeatedly building Docker containers. You’ll need the docker daemon v19.03 or newer available.
A Cluster
You’ll likely want an existing cluster as your management cluster. The easiest way to do this is with kind v0.9 or newer, as explained in the quick start.
Make sure your cluster is set as the default for kubectl.
If it’s not, you will need to modify subsequent kubectl commands below.
A container registry
If you’re using kind, you’ll need a way to push your images to a registry so they can be pulled. You can instead side-load all images, but the registry workflow is lower-friction.
Most users test with GCR, but you could also use something like Docker Hub.
If you choose not to use GCR, you’ll need to set the REGISTRY environment variable.
Kustomize
You’ll need to install kustomize.
There is a version of kustomize built into kubectl, but it does not have all the features of kustomize v3 and will not work.
Kubebuilder
You’ll need to install kubebuilder.
Envsubst
You’ll need envsubst or similar to handle clusterctl var replacement. Note: drone/envsubst releases v1.0.2 and earlier do not have the binary packaged under cmd/envsubst. It is available in Go pseudo-version v1.0.3-0.20200709231038-aa43e1c1a629
We provide a make target to generate the envsubst binary if desired. See the provider contract for more details about how clusterctl uses variables.
make envsubst
The generated binary can be found at ./hack/tools/bin/envsubst
Cert-Manager
You’ll need to deploy cert-manager components on your management cluster, using kubectl
kubectl apply -f https://github.com/jetstack/cert-manager/releases/download/v1.5.3/cert-manager.yaml
Ensure the cert-manager webhook service is ready before creating the Cluster API components.
This can be done by running:
kubectl wait --for=condition=Available --timeout=300s apiservice v1beta1.webhook.cert-manager.io
Development
Option 1: Tilt
Tilt is a tool for quickly building, pushing, and reloading Docker containers as part of a Kubernetes deployment. Many of the Cluster API engineers use it for quick iteration. Please see our Tilt instructions to get started.
Option 2: The Old-fashioned way
Building everything
You’ll need to build two docker images, one for Cluster API itself and one for the Docker provider (CAPD).
make docker-build
make -C test/infrastructure/docker docker-build
Push both images
$ make docker-push
docker push gcr.io/cluster-api-242700/cluster-api-controller-amd64:dev
The push refers to repository [gcr.io/cluster-api-242700/cluster-api-controller-amd64]
90a39583ad5f: Layer already exists
932da5156413: Layer already exists
dev: digest: sha256:263262cfbabd3d1add68172a5a1d141f6481a2bc443672ce80778dc122ee6234 size: 739
$ make -C test/infrastructure/docker docker-push
make: Entering directory '/home/liz/src/sigs.k8s.io/cluster-api/test/infrastructure/docker'
docker push gcr.io/cluster-api-242700/manager:dev
The push refers to repository [gcr.io/cluster-api-242700/manager]
5b1e744b2bae: Pushed
932da5156413: Layer already exists
dev: digest: sha256:35670a049372ae063dad910c267a4450758a139c4deb248c04c3198865589ab2 size: 739
make: Leaving directory '/home/liz/src/sigs.k8s.io/cluster-api/test/infrastructure/docker'
Make a note of the URLs and the digests. You’ll need them for the next step. In this case, they’re...
gcr.io/cluster-api-242700/manager@sha256:35670a049372ae063dad910c267a4450758a139c4deb248c04c3198865589ab2
and
gcr.io/cluster-api-242700/cluster-api-controller-amd64@sha256:263262cfbabd3d1add68172a5a1d141f6481a2bc443672ce80778dc122ee6234
Edit the manifests
$EDITOR config/manager/manager_image_patch.yaml
$EDITOR test/infrastructure/docker/config/manager/manager_image_patch.yaml
In both cases, change the - image: url to the digest URL mentioned above:
apiVersion: apps/v1
kind: Deployment
metadata:
name: controller-manager
namespace: system
spec:
template:
spec:
containers:
- image: gcr.io/cluster-api-242700/manager@sha256:35670a049372ae063dad910c267a4450758a139c4deb248c04c3198865589ab2`
name: manager
Apply the manifests
$ kustomize build config/ | ./hack/tools/bin/envsubst | kubectl apply -f -
namespace/capi-system configured
customresourcedefinition.apiextensions.k8s.io/clusters.cluster.x-k8s.io configured
customresourcedefinition.apiextensions.k8s.io/kubeadmconfigs.bootstrap.cluster.x-k8s.io configured
customresourcedefinition.apiextensions.k8s.io/kubeadmconfigtemplates.bootstrap.cluster.x-k8s.io configured
customresourcedefinition.apiextensions.k8s.io/machinedeployments.cluster.x-k8s.io configured
customresourcedefinition.apiextensions.k8s.io/machines.cluster.x-k8s.io configured
customresourcedefinition.apiextensions.k8s.io/machinesets.cluster.x-k8s.io configured
role.rbac.authorization.k8s.io/capi-leader-election-role configured
clusterrole.rbac.authorization.k8s.io/capi-manager-role configured
rolebinding.rbac.authorization.k8s.io/capi-leader-election-rolebinding configured
clusterrolebinding.rbac.authorization.k8s.io/capi-manager-rolebinding configured
deployment.apps/capi-controller-manager created
$ kustomize build test/infrastructure/docker/config | ./hack/tools/bin/envsubst | kubectl apply -f -
namespace/capd-system configured
customresourcedefinition.apiextensions.k8s.io/dockerclusters.infrastructure.cluster.x-k8s.io configured
customresourcedefinition.apiextensions.k8s.io/dockermachines.infrastructure.cluster.x-k8s.io configured
customresourcedefinition.apiextensions.k8s.io/dockermachinetemplates.infrastructure.cluster.x-k8s.io configured
role.rbac.authorization.k8s.io/capd-leader-election-role configured
clusterrole.rbac.authorization.k8s.io/capd-manager-role configured
clusterrole.rbac.authorization.k8s.io/capd-proxy-role configured
rolebinding.rbac.authorization.k8s.io/capd-leader-election-rolebinding configured
clusterrolebinding.rbac.authorization.k8s.io/capd-manager-rolebinding configured
clusterrolebinding.rbac.authorization.k8s.io/capd-proxy-rolebinding configured
service/capd-controller-manager-metrics-service created
deployment.apps/capd-controller-manager created
Check the status of the clusters
$ kubectl get po -n capd-system
NAME READY STATUS RESTARTS AGE
capd-controller-manager-7568c55d65-ndpts 2/2 Running 0 71s
$ kubectl get po -n capi-system
NAME READY STATUS RESTARTS AGE
capi-controller-manager-bf9c6468c-d6msj 1/1 Running 0 2m9s
Testing
Cluster API has a number of test suites available for you to run. Please visit the testing page for more information on each suite.
That’s it!
Now you can create CAPI objects! To test another iteration, you’ll need to follow the steps to build, push, update the manifests, and apply.
Videos explaining CAPI architecture and code walkthrough
CAPI components and architecture
- Cluster API Deep Dive - Dec 2020 v1alpha3
- Cluster API Deep Dive - Sept 2020 v1alpha3
- Declarative Kubernetes Clusters with Cluster API - Oct 2020 v1alpha3
Code walkthrough
Repository Layout
This page is still being written - stay tuned!
Developing Cluster API with Tilt
Overview
This document describes how to use kind and Tilt for a simplified workflow that offers easy deployments and rapid iterative builds.
Prerequisites
- Docker v19.03 or newer
- kind v0.9 or newer (other clusters can be
used if
preload_images_for_kindis set to false) - kustomize
standalone (
kubectl kustomizedoes not work because it is missing some features of kustomize v3) - Tilt v0.16.0 or newer
- envsubst or similar to handle
clusterctl var replacement. Note: drone/envsubst releases v1.0.2 and
earlier do not have the binary packaged under cmd/envsubst. It is
available in Go pseudo-version
v1.0.3-0.20200709231038-aa43e1c1a629 - Clone the Cluster API repository locally
- Clone the provider(s) you want to deploy locally as well
We provide a make target to generate the envsubst binary if desired. See the provider contract for more details about how clusterctl uses variables.
make envsubst
Getting started
Create a kind cluster
First, make sure you have a kind cluster and that your KUBECONFIG is set up correctly:
kind create cluster
IMPORTANT, if you are planning to use the CAPD provider, check that you created the required mounts for allowing the provider to access the Docker socket on the host; see quick start for instructions.
Create a tilt-settings.json file
Next, create a tilt-settings.json file and place it in your local copy of cluster-api. Here is an example:
{
"default_registry": "gcr.io/your-project-name-here",
"provider_repos": ["../cluster-api-provider-aws"],
"enable_providers": ["aws", "docker", "kubeadm-bootstrap", "kubeadm-control-plane"]
}
tilt-settings.json fields
allowed_contexts (Array, default=[]): A list of kubeconfig contexts Tilt is allowed to use. See the Tilt documentation on allow_k8s_contexts for more details.
default_registry (String, default=””): The image registry to use if you need to push images. See the Tilt documentation for more details.
provider_repos (Array[]String, default=[]): A list of paths to all the providers you want to use. Each provider must have a
tilt-provider.json file describing how to build the provider.
enable_providers (Array[]String, default=[‘docker’]): A list of the providers to enable. See available providers for more details.
kind_cluster_name (String, default=”kind”): The name of the kind cluster to use when preloading images.
kustomize_substitutions (Map{String: String}, default={}): An optional map of substitutions for ${}-style placeholders in the
provider’s yaml.
For example, if the yaml contains ${AWS_B64ENCODED_CREDENTIALS}, you could do the following:
"kustomize_substitutions": {
"AWS_B64ENCODED_CREDENTIALS": "your credentials here"
}
An Azure Service Principal is needed for populating the controller manifests. This utilizes environment-based authentication.
- Save your Subscription ID
AZURE_SUBSCRIPTION_ID=$(az account show --query id --output tsv)
az account set --subscription $AZURE_SUBSCRIPTION_ID
- Set the Service Principal name
AZURE_SERVICE_PRINCIPAL_NAME=ServicePrincipalName
- Save your Tenant ID, Client ID, Client Secret
AZURE_TENANT_ID=$(az account show --query tenantId --output tsv)
AZURE_CLIENT_SECRET=$(az ad sp create-for-rbac --name http://$AZURE_SERVICE_PRINCIPAL_NAME --query password --output tsv)
AZURE_CLIENT_ID=$(az ad sp show --id http://$AZURE_SERVICE_PRINCIPAL_NAME --query appId --output tsv)
Add the output of the following as a section in your tilt-settings.json:
cat <<EOF
"kustomize_substitutions": {
"AZURE_SUBSCRIPTION_ID_B64": "$(echo "${AZURE_SUBSCRIPTION_ID}" | tr -d '\n' | base64 | tr -d '\n')",
"AZURE_TENANT_ID_B64": "$(echo "${AZURE_TENANT_ID}" | tr -d '\n' | base64 | tr -d '\n')",
"AZURE_CLIENT_SECRET_B64": "$(echo "${AZURE_CLIENT_SECRET}" | tr -d '\n' | base64 | tr -d '\n')",
"AZURE_CLIENT_ID_B64": "$(echo "${AZURE_CLIENT_ID}" | tr -d '\n' | base64 | tr -d '\n')"
}
EOF
"kustomize_substitutions": {
"DO_B64ENCODED_CREDENTIALS": "your credentials here"
}
You can generate a base64 version of your GCP json credentials file using:
base64 -i ~/path/to/gcp/credentials.json
"kustomize_substitutions": {
"GCP_B64ENCODED_CREDENTIALS": "your credentials here"
}
deploy_cert_manager (Boolean, default=true): Deploys cert-manager into the cluster for use for webhook registration.
preload_images_for_kind (Boolean, default=true): Uses kind load docker-image to preload images into a kind cluster.
trigger_mode (String, default=auto): Optional setting to configure if tilt should automatically rebuild on changes.
Set to manual to disable auto-rebuilding and require users to trigger rebuilds of individual changed components through the UI.
extra_args (Object, default={}): A mapping of provider to additional arguments to pass to the main binary configured for this provider. Each item in the array will be passed in to the manager for the given provider.
Example:
{
"extra_args": {
"core": ["--feature-gates=MachinePool=true"],
"kubeadm-bootstrap": ["--feature-gates=MachinePool=true"],
"azure": ["--feature-gates=MachinePool=true"]
}
}
With this config, the respective managers will be invoked with:
manager --feature-gates=MachinePool=true
Run Tilt!
To launch your development environment, run
tilt up
This will open the command-line HUD as well as a web browser interface. You can monitor Tilt’s status in either location. After a brief amount of time, you should have a running development environment, and you should now be able to create a cluster. There are example worker cluster configs available. These can be customized for your specific needs.
Available providers
The following providers are currently defined in the Tiltfile:
- core: cluster-api itself (Cluster/Machine/MachineDeployment/MachineSet/KubeadmConfig/KubeadmControlPlane)
- docker: Docker provider (DockerCluster/DockerMachine)
tilt-provider.json
A provider must supply a tilt-provider.json file describing how to build it. Here is an example:
{
"name": "aws",
"config": {
"image": "gcr.io/k8s-staging-cluster-api-aws/cluster-api-aws-controller",
"live_reload_deps": [
"main.go", "go.mod", "go.sum", "api", "cmd", "controllers", "pkg"
]
}
}
config fields
image: the image for this provider, as referenced in the kustomize files. This must match; otherwise, Tilt won’t build it.
live_reload_deps: a list of files/directories to watch. If any of them changes, Tilt rebuilds the manager binary for the provider and performs a live update of the running container.
additional_docker_helper_commands (String, default=””): Additional commands to be run in the helper image docker build. e.g.
RUN wget -qO- https://dl.k8s.io/v1.21.2/kubernetes-client-linux-amd64.tar.gz | tar xvz
RUN wget -qO- https://get.docker.com | sh
additional_docker_build_commands (String, default=””): Additional commands to be appended to
the dockerfile.
The manager image will use docker-slim, so to download files, use additional_helper_image_commands. e.g.
COPY --from=tilt-helper /usr/bin/docker /usr/bin/docker
COPY --from=tilt-helper /go/kubernetes/client/bin/kubectl /usr/bin/kubectl
kustomize_config (Bool, default=true): Whether or not running kustomize on the ./config folder of the provider.
Set to false if your provider does not have a ./config folder or you do not want it to be applied in the cluster.
go_main (String, default=”main.go”): The go main file if not located at the root of the folder
Customizing Tilt
If you need to customize Tilt’s behavior, you can create files in cluster-api’s tilt.d directory. This file is ignored
by git so you can be assured that any files you place here will never be checked in to source control.
These files are included after the providers map has been defined and after all the helper function definitions. This
is immediately before the “real work” happens.
Under the covers, a.k.a “the real work”
At a high level, the Tiltfile performs the following actions:
- Read
tilt-settings.json - Configure the allowed Kubernetes contexts
- Set the default registry
- Define the
providersmap - Include user-defined Tilt files
- Deploy cert-manager
- Enable providers (
core+ what is listed intilt-settings.json)- Build the manager binary locally as a
local_resource - Invoke
docker_buildfor the provider - Invoke
kustomizefor the provider’sconfig/directory
- Build the manager binary locally as a
Live updates
Each provider in the providers map has a live_reload_deps list. This defines the files and/or directories that Tilt
should monitor for changes. When a dependency is modified, Tilt rebuilds the provider’s manager binary on your local
machine, copies the binary to the running container, and executes a restart script. This is significantly faster
than rebuilding the container image for each change. It also helps keep the size of each development image as small as
possible (the container images do not need the entire go toolchain, source code, module dependencies, etc.).
Testing Cluster API
This document presents testing guidelines and conventions for Cluster API.
IMPORTANT: improving and maintaining this document is a collaborative effort, so we are encouraging constructive feedback and suggestions.
Unit tests
Unit tests focus on individual pieces of logic - a single func - and don’t require any additional services to execute. They should be fast and great for getting the first signal on the current implementation, but unit tests have the risk of allowing integration bugs to slip through.
Historically, in Cluster API unit tests were developed using go test, gomega and the fakeclient; see the quick reference below.
However, considering some changes introduced in the v0.3.x releases (e.g. ObservedGeneration, Conditions), there is a common agreement among Cluster API maintainers that using fakeclient should be progressively deprecated in favor of using envtest. See the quick reference below.
Integration tests
Integration tests are focused on testing the behavior of an entire controller or the interactions between two or more Cluster API controllers.
In older versions of Cluster API, integration tests were based on a real cluster and meant to be run in CI only; however, now we are considering a different approach based on envtest and with one or more controllers configured to run against the test cluster.
With this approach it is possible to interact with Cluster API like in a real environment, by creating/updating Kubernetes objects and waiting for the controllers to take action.
Please note that while using this mode, as of today, when testing the interactions with an infrastructure provider some infrastructure components will be generated, and this could have relevant impacts on test durations (and requirements).
While, as of today this is a strong limitation, in the future we might consider to have a “dry-run” option in CAPD or a fake infrastructure provider to allow test coverage for testing the interactions with an infrastructure provider as well.
Running unit and integration tests
Run make test to execute all unit and integration tests.
End-to-end tests
The end-to-end tests are meant to verify the proper functioning of a Cluster API management cluster in an environment that resemble a real production environment.
The following guidelines should be followed when developing E2E tests:
- Use the Cluster API test framework.
- Define test spec reflecting real user workflow, e.g. Cluster API quick start.
- Unless you are testing provider specific features, ensure your test can run with different infrastructure providers (see Writing Portable Tests).
See e2e development for more information on developing e2e tests for CAPI and external providers.
Running the end-to-end tests locally
Usually the e2e tests are executed by Prow, either pre-submit (on PRs) or periodically on certain branches (e.g. the default branch). Those jobs are defined in the kubernetes/test-infra repository in config/jobs/kubernetes-sigs/cluster-api. For development and debugging those tests can also be executed locally.
Prerequisites
make docker-build-e2e will build the images for all providers that will be needed for the e2e tests.
Test execution via ci-e2e.sh
To run a test locally via the command line, you should look at the Prow Job configuration for the test you want to run and then execute the same commands locally. For example to run pull-cluster-api-e2e-main just execute:
GINKGO_FOCUS="\[PR-Blocking\]" ./scripts/ci-e2e.sh
Test execution via make test-e2e
make test-e2e will run e2e tests by using whatever provider images already exist on disk.
After running make docker-build-e2e at least once, make test-e2e can be used for a faster test run, if there are no
provider code changes. If the provider code is changed, run make docker-build-e2e to update the images.
Test execution via IDE
It’s also possible to run the tests via an IDE which makes it easier to debug the test code by stepping through the code.
First, we have to make sure all prerequisites are fulfilled, i.e. all required images have been built (this also includes
kind images). This can be done by executing the ./scripts/ci-e2e.sh script.
# Notes:
# * You can cancel the script as soon as it starts the actual test execution via `make -C test/e2e/ run`.
# * If you want to run other tests (e.g. upgrade tests), make sure all required env variables are set (see the Prow Job config).
GINKGO_FOCUS="\[PR-Blocking\]" ./scripts/ci-e2e.sh
# Make sure the cluster-templates have been generated.
make -C test/e2e cluster-templates
Now, the tests can be run in an IDE. The following describes how this can be done in Intellij IDEA and VS Code. It should work
roughly the same way in all other IDEs. We assume the cluster-api repository has been checked
out into /home/user/code/src/sigs.k8s.io/cluster-api.
Intellij
Create a new run configuration and fill in:
- Test framework:
gotest - Test kind:
Package - Package path:
sigs.k8s.io/cluster-api/test/e2e - Pattern:
^\QTestE2E\E$ - Working directory:
/home/user/code/src/sigs.k8s.io/cluster-api/test/e2e - Environment:
ARTIFACTS=/home/user/code/src/sigs.k8s.io/cluster-api/_artifacts - Program arguments:
-e2e.config=/home/user/code/src/sigs.k8s.io/cluster-api/test/e2e/config/docker.yaml -ginkgo.focus="\[PR-Blocking\]"
VS Code
Add the launch.json file in the .vscode folder in your repo:
{
"version": "0.2.0",
"configurations": [
{
"name": "Run e2e test",
"type": "go",
"request": "launch",
"mode": "test",
"program": "${workspaceRoot}/test/e2e/e2e_suite_test.go",
"env": {
"ARTIFACTS":"${workspaceRoot}/_artifacts",
},
"args": [
"-e2e.config=${workspaceRoot}/test/e2e/config/docker.yaml",
"-ginkgo.focus=\\[PR-Blocking\\]",
"-ginkgo.v=true"
],
"trace": "verbose",
"buildFlags": "-tags 'e2e'",
"showGlobalVariables": true
}
]
}
Execute the run configuration with Debug.
Running specific tests
To run a subset of tests, a combination of either one or both of GINKGO_FOCUS and GINKGO_SKIP env variables can be set.
Each of these can be used to match tests, for example:
[PR-Blocking]=> Sanity tests run before each PR merge[K8s-Upgrade]=> Tests which verify k8s component version upgrades on workload clusters[Conformance]=> Tests which run the k8s conformance suite on workload clustersWhen testing KCP.*=> Tests which start withWhen testing KCP
For example:
GINKGO_FOCUS="\\[PR-Blocking\\]" make test-e2e can be used to run the sanity E2E tests
GINKGO_SKIP="\\[K8s-Upgrade\\]" make test-e2e can be used to skip the upgrade E2E tests
Further customization
The following env variables can be set to customize the test execution:
GINKGO_FOCUSto set ginkgo focus (default empty - all tests)GINKGO_SKIPto set ginkgo skip (default empty - to allow running all tests)GINKGO_NODESto set the number of ginkgo parallel nodes (default to 1)E2E_CONF_FILEto set the e2e test config file (default to ${REPO_ROOT}/test/e2e/config/docker.yaml)ARTIFACTSto set the folder where test artifact will be stored (default to ${REPO_ROOT}/_artifacts)SKIP_RESOURCE_CLEANUPto skip resource cleanup at the end of the test (useful for problem investigation) (default to false)USE_EXISTING_CLUSTERto use an existing management cluster instead of creating a new one for each test run (default to false)GINKGO_NOCOLORto turn off the ginkgo colored output (default to false)
Furthermore, it’s possible to overwrite all env variables specified in variables in test/e2e/config/docker.yaml.
Quick reference
envtest
envtest is a testing environment that is provided by the controller-runtime project. This environment spins up a local instance of etcd and the kube-apiserver. This allows tests to be executed in an environment very similar to a real environment.
Additionally, in Cluster API there is a set of utilities under [internal/envtest] that helps developers in setting up a envtest ready for Cluster API testing, and more specifically:
- With the required CRDs already pre-configured.
- With all the Cluster API webhook pre-configured, so there are enforced guarantees about the semantic accuracy of the test objects you are going to create.
This is an example of how to create an instance of envtest that can be shared across all the tests in a package;
by convention, this code should be in a file named suite_test.go:
var (
env *envtest.Environment
ctx = ctrl.SetupSignalHandler()
)
func TestMain(m *testing.M) {
setupIndexes := func(ctx context.Context, mgr ctrl.Manager) {
if err := index.AddDefaultIndexes(ctx, mgr); err != nil {
panic(fmt.Sprintf("unable to setup index: %v", err))
}
}
setupReconcilers := func(ctx context.Context, mgr ctrl.Manager) {
if err := (&MyReconciler{
Client: mgr.GetClient(),
Log: log.NullLogger{},
}).SetupWithManager(mgr, controller.Options{MaxConcurrentReconciles: 1}); err != nil {
panic(fmt.Sprintf("Failed to start the MyReconciler: %v", err))
}
}
os.Exit(envtest.Run(ctx, envtest.RunInput{
M: m,
SetupEnv: func(e *envtest.Environment) { env = e },
SetupIndexes: setupIndexes,
SetupReconcilers: setupReconcilers,
}))
}
Most notably, envtest provides not only a real API server to use during testing, but it offers the opportunity to configure one or more controllers to run against the test cluster. By using this feature it is possible to use envtest for developing Cluster API integration tests.
func TestMain(m *testing.M) {
// Bootstrapping test environment
...
setupReconcilers := func(ctx context.Context, mgr ctrl.Manager) {
if err := (&MyReconciler{
Client: mgr.GetClient(),
Log: log.NullLogger{},
}).SetupWithManager(mgr, controller.Options{MaxConcurrentReconciles: 1}); err != nil {
panic(fmt.Sprintf("Failed to start the MyReconciler: %v", err))
}
}
// Run tests
...
}
Please note that, because envtest uses a real kube-apiserver that is shared across many tests, the developer should take care in ensuring each test runs in isolation from the others, by:
- Creating objects in separated namespaces.
- Avoiding object name conflict.
However, developers should be aware that in some ways, the test control plane will behave differently from “real” clusters, and that might have an impact on how you write tests.
One common example is garbage collection; because there are no controllers monitoring built-in resources, objects do not get deleted, even if an OwnerReference is set up; as a consequence, usually test implements code for cleaning up created objects.
This is an example of a test implementing those recommendations:
func TestAFunc(t *testing.T) {
g := NewWithT(t)
// Generate namespace with a random name starting with ns1; such namespace
// will host test objects in isolation from other tests.
ns1, err := env.CreateNamespace(ctx, "ns1")
g.Expect(err).ToNot(HaveOccurred())
defer func() {
// Cleanup the test namespace
g.Expect(env.DeleteNamespace(ctx, ns1)).To(Succeed())
}()
obj := &clusterv1.Cluster{
ObjectMeta: metav1.ObjectMeta{
Name: "test",
Namespace: ns1.Name, // Place test objects in the test namespace
},
}
// Actual test code...
}
In case of object used in many test case within the same test, it is possible to leverage on Kubernetes GenerateName;
For objects that are shared across sub-tests, ensure they are scoped within the test namespace and deep copied to avoid
cross-test changes that may occur to the object.
func TestAFunc(t *testing.T) {
g := NewWithT(t)
// Generate namespace with a random name starting with ns1; such namespace
// will host test objects in isolation from other tests.
ns1, err := env.CreateNamespace(ctx, "ns1")
g.Expect(err).ToNot(HaveOccurred())
defer func() {
// Cleanup the test namespace
g.Expect(env.DeleteNamespace(ctx, ns1)).To(Succeed())
}()
obj := &clusterv1.Cluster{
ObjectMeta: metav1.ObjectMeta{
GenerateName: "test-", // Instead of assigning a name, use GenerateName
Namespace: ns1.Name, // Place test objects in the test namespace
},
}
t.Run("test case 1", func(t *testing.T) {
g := NewWithT(t)
// Deep copy the object in each test case, so we prevent side effects in case the object changes.
// Additionally, thanks to GenerateName, the objects gets a new name for each test case.
obj := obj.DeepCopy()
// Actual test case code...
}
t.Run("test case 2", func(t *testing.T) {
g := NewWithT(t)
obj := obj.DeepCopy()
// Actual test case code...
}
// More test cases.
}
fakeclient
fakeclient is another utility that is provided by the controller-runtime project. While this utility is really fast and simple to use because it does not require to spin-up an instance of etcd and kube-apiserver, the fakeclient comes with a set of limitations that could hamper the validity of a test, most notably:
- it does not properly handle a set of fields which are common in the Kubernetes API objects (and Cluster API objects as well)
like e.g.
creationTimestamp,resourceVersion,generation,uid - API calls doe not execute defaulting or validation webhooks, so there are no enforced guarantees about the semantic accuracy of the test objects.
Historically, fakeclient is widely used in Cluster API, however, given the growing relevance of the above limitations with regard to some changes introduced in the v0.3.x releases (e.g. ObservedGeneration, Conditions), there is a common agreement among Cluster API maintainers that using fakeclient should be progressively deprecated in favor of use of envtest.
ginkgo
Ginkgo is a Go testing framework built to help you efficiently write expressive and comprehensive tests using Behavior-Driven Development (“BDD”) style.
While Ginkgo is widely used in the Kubernetes ecosystem, Cluster API maintainers found the lack of integration with the most used golang IDE somehow limiting, mostly because:
- it makes interactive debugging of tests more difficult, since you can’t just run the test using the debugger directly
- it makes it more difficult to only run a subset of tests, since you can’t just run or debug individual tests using an IDE,
but you now need to run the tests using
makeor theginkgocommand line and override the focus to select individual tests
In Cluster API you MUST use ginkgo only for E2E tests, where it is required to leverage the support for running specs
in parallel; in any case, developers MUST NOT use the table driven extension DSL (DescribeTable, Entry commands)
which is considered unintuitive.
gomega
Gomega is a matcher/assertion library. It is usually paired with the Ginkgo BDD test framework, but it can be used with other test frameworks too.
More specifically, in order to use Gomega with go test you should
func TestFarmHasCow(t *testing.T) {
g := NewWithT(t)
g.Expect(f.HasCow()).To(BeTrue(), "Farm should have cow")
}
In Cluster API all the test MUST use Gomega assertions.
go test
go test testing provides support for automated testing of Go packages.
In Cluster API Unit and integration test MUST use go test.
Developing E2E tests
E2E tests are meant to verify the proper functioning of a Cluster API management cluster in an environment that resembles a real production environment.
The following guidelines should be followed when developing E2E tests:
- Use the Cluster API test framework.
- Define test spec reflecting real user workflow, e.g. Cluster API quick start.
- Unless you are testing provider specific features, ensure your test can run with different infrastructure providers (see Writing Portable Tests).
The Cluster API test framework provides you a set of helper methods for getting your test in place quickly. The test E2E package provides examples of how this can be achieved and reusable test specs for the most common Cluster API use cases.
Prerequisites
Each E2E test requires a set of artifacts to be available:
- Binaries & docker images for Kubernetes, CNI, CRI & CSI
- Manifests & docker images for the Cluster API core components
- Manifests & docker images for the Cluster API infrastructure provider; in most cases machine images are also required (AMI, OVA etc.)
- Credentials for the target infrastructure provider
- Other support tools (e.g. kustomize, gsutil etc.)
The Cluster API test framework provides support for building and retrieving the manifest files for Cluster API core components and for the Cluster API infrastructure provider (see Setup).
For the remaining tasks you can find examples of how this can be implemented e.g. in CAPA E2E tests and CAPG E2E tests.
Setup
In order to run E2E tests it is required to create a Kubernetes cluster with a
complete set of Cluster API providers installed. Setting up those elements is
usually implemented in a BeforeSuite function, and it consists of two steps:
- Defining an E2E config file
- Creating the management cluster and installing providers
Defining an E2E config file
The E2E config file provides a convenient and flexible way to define common tasks for setting up a management cluster.
Using the config file it is possible to:
- Define the list of providers to be installed in the management cluster. Most notably,
for each provider it is possible to define:
- One or more versions of the providers manifest (built from the sources, or pulled from a remote location).
- A list of additional files to be added to the provider repository, to be used e.g.
to provide
cluster-templates.yamlfiles.
- Define the list of variables to be used when doing
clusterctl initorclusterctl generate cluster. - Define a list of intervals to be used in the test specs for defining timeouts for the
wait and
Eventuallymethods. - Define the list of images to be loaded in the management cluster (this is specific to management clusters based on kind).
An example E2E config file can be found here.
Creating the management cluster and installing providers
In order to run Cluster API E2E tests, you need a Kubernetes cluster. The NewKindClusterProvider gives you a type that can be used to create a local kind cluster and pre-load images into it. Existing clusters can be used if available.
Once you have a Kubernetes cluster, the InitManagementClusterAndWatchControllerLogs method provides a convenient way for installing providers.
This method:
- Runs
clusterctl initusing the above local repository. - Waits for the providers controllers to be running.
- Creates log watchers for all the providers
Writing test specs
A typical test spec is a sequence of:
- Creating a namespace to host in isolation all the test objects.
- Creating objects in the management cluster, wait for the corresponding infrastructure to be provisioned.
- Exec operations like e.g. changing the Kubernetes version or
clusterctl move, wait for the action to complete. - Delete objects in the management cluster, wait for the corresponding infrastructure to be terminated.
Creating Namespaces
The CreateNamespaceAndWatchEvents method provides a convenient way to create a namespace and setup watches for capturing namespaces events.
Creating objects
There are two possible approaches for creating objects in the management cluster:
- Create object by object: create the
Clusterobject, thenAwsCluster,Machines,AwsMachinesetc. - Apply a
cluster-templates.yamlfile thus creating all the objects this file contains.
The first approach leverages the controller-runtime Client and gives you full control, but it comes with some drawbacks as well, because this method does not directly reflect real user workflows, and most importantly, the resulting tests are not as reusable with other infrastructure providers. (See writing portable tests).
We recommend using the ClusterTemplate method and the Apply method for creating objects in the cluster.
This methods mimics the recommended user workflows, and it is based on cluster-templates.yaml files that can be
provided via the E2E config file, and thus easily swappable when changing the target infrastructure provider.
After creating objects in the cluster, use the existing methods in the Cluster API test framework to discover
which object were created in the cluster so your code can adapt to different cluster-templates.yaml files.
Once you have object references, the framework includes methods for waiting for the corresponding infrastructure to be provisioned, e.g. WaitForClusterToProvision, WaitForKubeadmControlPlaneMachinesToExist.
Exec operations
You can use Cluster API test framework methods to modify Cluster API objects, as a last option, use the controller-runtime Client.
The Cluster API test framework also includes methods for executing clusterctl operations, like e.g. the ClusterTemplate method, the ClusterctlMove method etc.. In order to improve observability, each clusterctl operation creates a detailed log.
After using clusterctl operations, you can rely on the Get and on the Wait methods
defined in the Cluster API test framework to check if the operation completed successfully.
Naming the test spec
You can categorize the test with a custom label that can be used to filter a category of E2E tests to be run. Currently, the cluster-api codebase has these labels which are used to run a focused subset of tests.
Tear down
After a test completes/fails, it is required to:
- Collect all the logs for the Cluster API controllers
- Dump all the relevant Cluster API/Kubernetes objects
- Cleanup all the infrastructure resources created during the test
Those tasks are usually implemented in the AfterSuite, and again the Cluster API test framework provides
you useful methods for those tasks.
Please note that despite the fact that test specs are expected to delete objects in the management cluster and wait for the corresponding infrastructure to be terminated, it can happen that the test spec fails before starting object deletion or that objects deletion itself fails.
As a consequence, when scheduling/running a test suite, it is required to ensure all the generated resources are cleaned up. In Kubernetes, this is implemented by the boskos project.
Writing portable E2E tests
A portable E2E test is a test that can run with different infrastructure providers by simply changing the test configuration file.
The following recommendations should be followed to write portable E2E tests:
- Create different E2E config file, one for each target infrastructure provider, providing different sets of env variables and timeout intervals.
- Use the [InitManagementCluster method] for setting up the management cluster.
- Use the ClusterTemplate method and the Apply method
for creating objects in the cluster using
cluster-templates.yamlfiles instead of hard coding object creation. - Use the
Getmethods defined in the Cluster API test framework to check objects being created, so your code can adapt to differentcluster-templates.yamlfiles. - Never hard code the infrastructure provider name in your test spec. Instead, use the InfrastructureProvider method to get access to the name of the infrastructure provider defined in the E2E config file.
- Never hard code wait intervals in your test spec. Instead use the GetIntervals method to get access to the intervals defined in the E2E config file.
Cluster API conformance tests
As of today there is no a well-defined suite of E2E tests that can be used as a baseline for Cluster API conformance.
However, creating such a suite is something that can provide a huge value for the long term success of the project.
The test E2E package provides examples of how this can be achieved by implementing a set of reusable test specs for the most common Cluster API use cases.
Controllers
This page is still being written - stay tuned!
Bootstrap Controller
Bootstrapping is the process in which:
- A cluster is bootstrapped
- A machine is bootstrapped and takes on a role within a cluster
CABPK is the reference bootstrap provider and is based on kubeadm. CABPK codifies the steps for creating a cluster in multiple configurations.
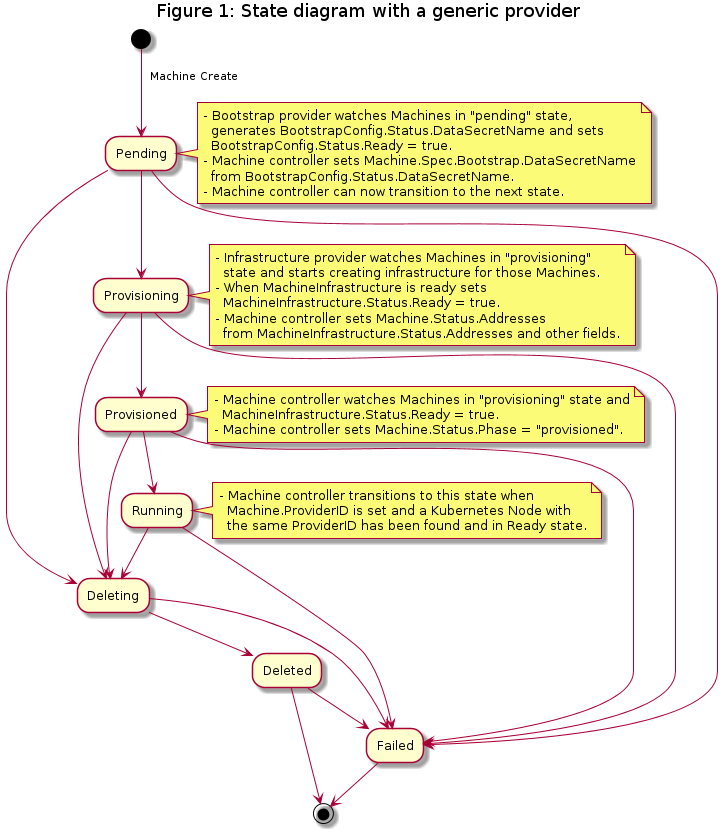
See proposal for the full details on how the bootstrap process works.
Implementations
- Kubeadm (Reference Implementation)
Cluster Controller
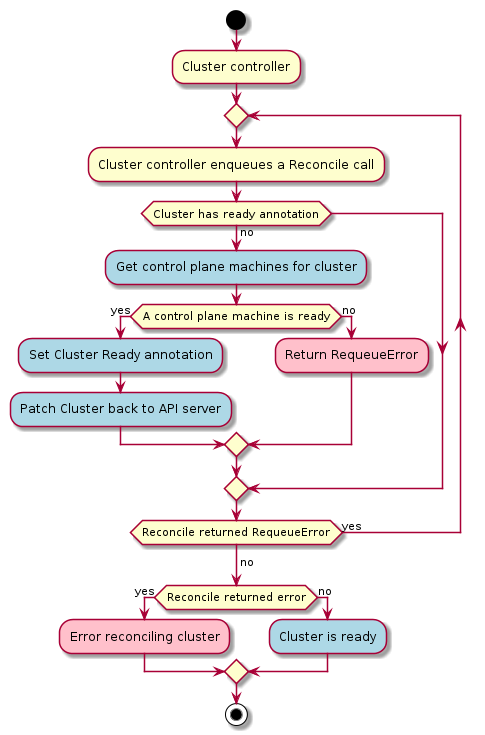
The Cluster controller’s main responsibilities are:
- Setting an OwnerReference on the infrastructure object referenced in
Cluster.Spec.InfrastructureRef. - Cleanup of all owned objects so that nothing is dangling after deletion.
- Keeping the Cluster’s status in sync with the infrastructure Cluster’s status.
- Creating a kubeconfig secret for workload clusters.
Contracts
Infrastructure Provider
The general expectation of an infrastructure provider is to provision the necessary infrastructure components needed to run a Kubernetes cluster. As an example, the AWS infrastructure provider, specifically the AWSCluster reconciler, will provision a VPC, some security groups, an ELB, a bastion instance and some other components all with AWS best practices baked in. Once that infrastructure is provisioned and ready to be used the AWSMachine reconciler takes over and provisions EC2 instances that will become a Kubernetes cluster through some bootstrap mechanism.
Required status fields
The InfrastructureCluster object must have a status object.
The spec object must have the following fields defined:
controlPlaneEndpoint- identifies the endpoint used to connect to the target’s cluster apiserver.
The status object must have the following fields defined:
ready- a boolean field that is true when the infrastructure is ready to be used.
Optional status fields
The status object may define several fields that do not affect functionality if missing:
failureReason- is a string that explains why a fatal error has occurred, if possible.failureMessage- is a string that holds the message contained by the error.
Example:
kind: MyProviderCluster
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3
spec:
controlPlaneEndpoint:
host: example.com
port: 6443
status:
ready: true
Secrets
If you are using the kubeadm bootstrap provider you do not have to provide any Cluster API secrets. It will generate all necessary CAs (certificate authorities) for you.
However, if you provide a CA for the cluster then Cluster API will be able to generate a kubeconfig secret. This is useful if you have a custom CA or do not want to use the bootstrap provider’s generated self-signed CA.
| Secret name | Field name | Content |
|---|---|---|
<cluster-name>-ca | tls.crt | base64 encoded TLS certificate in PEM format |
<cluster-name>-ca | tls.key | base64 encoded TLS private key in PEM format |
Alternatively can entirely bypass Cluster API generating a kubeconfig entirely if you provide a kubeconfig secret formatted as described below.
| Secret name | Field name | Content |
|---|---|---|
<cluster-name>-kubeconfig | value | base64 encoded kubeconfig |
Machine Controller
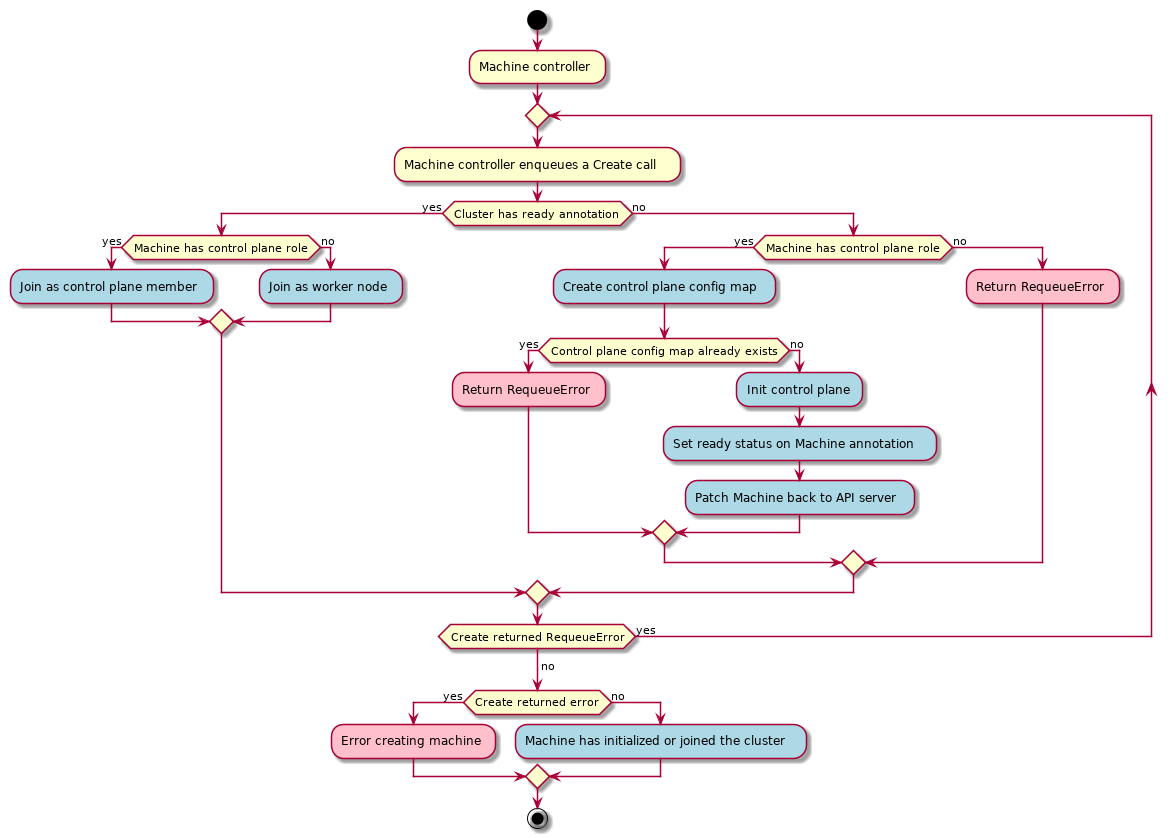
The Machine controller’s main responsibilities are:
- Setting an OwnerReference on:
- Each Machine object to the Cluster object.
- The associated BootstrapConfig object.
- The associated InfrastructureMachine object.
- Copy data from
BootstrapConfig.Status.DataSecretNametoMachine.Spec.Bootstrap.DataSecretNameifMachine.Spec.Bootstrap.DataSecretNameis empty. - Setting NodeRefs to be able to associate machines and kubernetes nodes.
- Deleting Nodes in the target cluster when the associated machine is deleted.
- Cleanup of related objects.
- Keeping the Machine’s Status object up to date with the InfrastructureMachine’s Status object.
- Finding Kubernetes nodes matching the expected providerID in the workload cluster.
After the machine controller sets the OwnerReferences on the associated objects, it waits for the bootstrap
and infrastructure objects referenced by the machine to have the Status.Ready field set to true. When
the infrastructure object is ready, the machine controller will attempt to read its Spec.ProviderID and
copy it into Machine.Spec.ProviderID.
The machine controller uses the kubeconfig for the new workload cluster to watch new nodes coming up.
When a node appears with Node.Spec.ProviderID matching Machine.Spec.ProviderID, the machine controller
transitions the associated machine into the Provisioned state. When the infrastructure ref is also
Ready, the machine controller marks the machine as Running.
Contracts
Cluster API
Cluster associations are made via labels.
Expected labels
| what | label | value | meaning |
|---|---|---|---|
| Machine | cluster.x-k8s.io/cluster-name | <cluster-name> | Identify a machine as belonging to a cluster with the name <cluster-name> |
| Machine | cluster.x-k8s.io/control-plane | true | Identifies a machine as a control-plane node |
Bootstrap provider
The BootstrapConfig object must have a status object.
To override the bootstrap provider, a user (or external system) can directly set the Machine.Spec.Bootstrap.Data
field. This will mark the machine as ready for bootstrapping and no bootstrap data will be copied from the
BootstrapConfig object.
Required status fields
The status object must have several fields defined:
ready- a boolean field indicating the bootstrap config data is generated and ready for use.dataSecretName- a string field referencing the name of the secret that stores the generated bootstrap data.
Optional status fields
The status object may define several fields that do not affect functionality if missing:
failureReason- a string field explaining why a fatal error has occurred, if possible.failureMessage- a string field that holds the message contained by the error.
Example:
kind: MyBootstrapProviderConfig
apiVersion: bootstrap.cluster.x-k8s.io/v1alpha3
status:
ready: true
dataSecretName: "MyBootstrapSecret"
Infrastructure provider
The InfrastructureMachine object must have both spec and status objects.
Required spec fields
The spec object must at least one field defined:
providerID- a cloud provider ID identifying the machine.
Required status fields
The status object must at least one field defined:
ready- a boolean field indicating if the infrastructure is ready to be used or not.
Optional status fields
The status object may define several fields that do not affect functionality if missing:
failureReason- is a string that explains why a fatal error has occurred, if possible.failureMessage- is a string that holds the message contained by the error.
Example:
kind: MyMachine
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3
spec:
providerID: cloud:////my-cloud-provider-id
status:
ready: true
Secrets
The Machine controller will create a secret or use an existing secret in the following format:
| secret name | field name | content |
|---|---|---|
<cluster-name>-kubeconfig | value | base64 encoded kubeconfig that is authenticated with the child cluster |
MachineSet
A MachineSet is an immutable abstraction over Machines.
Its main responsibilities are:
- Adopting unowned Machines that aren’t assigned to a MachineSet
- Adopting unmanaged Machines that aren’t assigned a Cluster
- Booting a group of N machines
- Monitoring the status of those booted machines
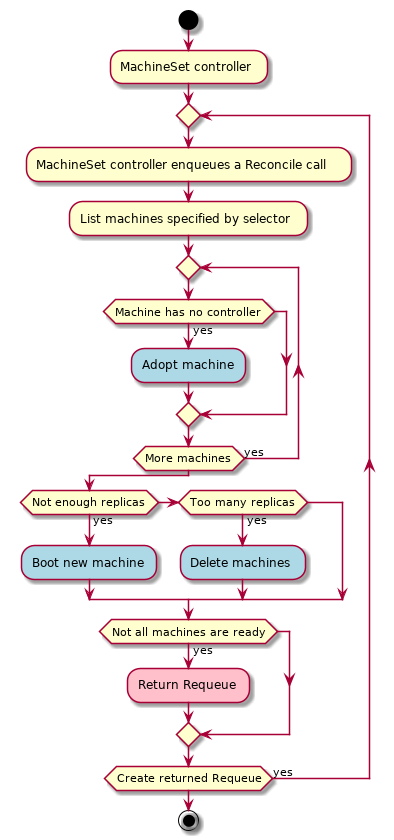
MachineDeployment
A MachineDeployment orchestrates deployments over a fleet of MachineSets.
Its main responsibilities are:
- Adopting matching MachineSets not assigned to a MachineDeployment
- Adopting matching MachineSets not assigned to a Cluster
- Managing the Machine deployment process
- Scaling up new MachineSets when changes are made
- Scaling down old MachineSets when newer MachineSets replace them
- Updating the status of MachineDeployment objects
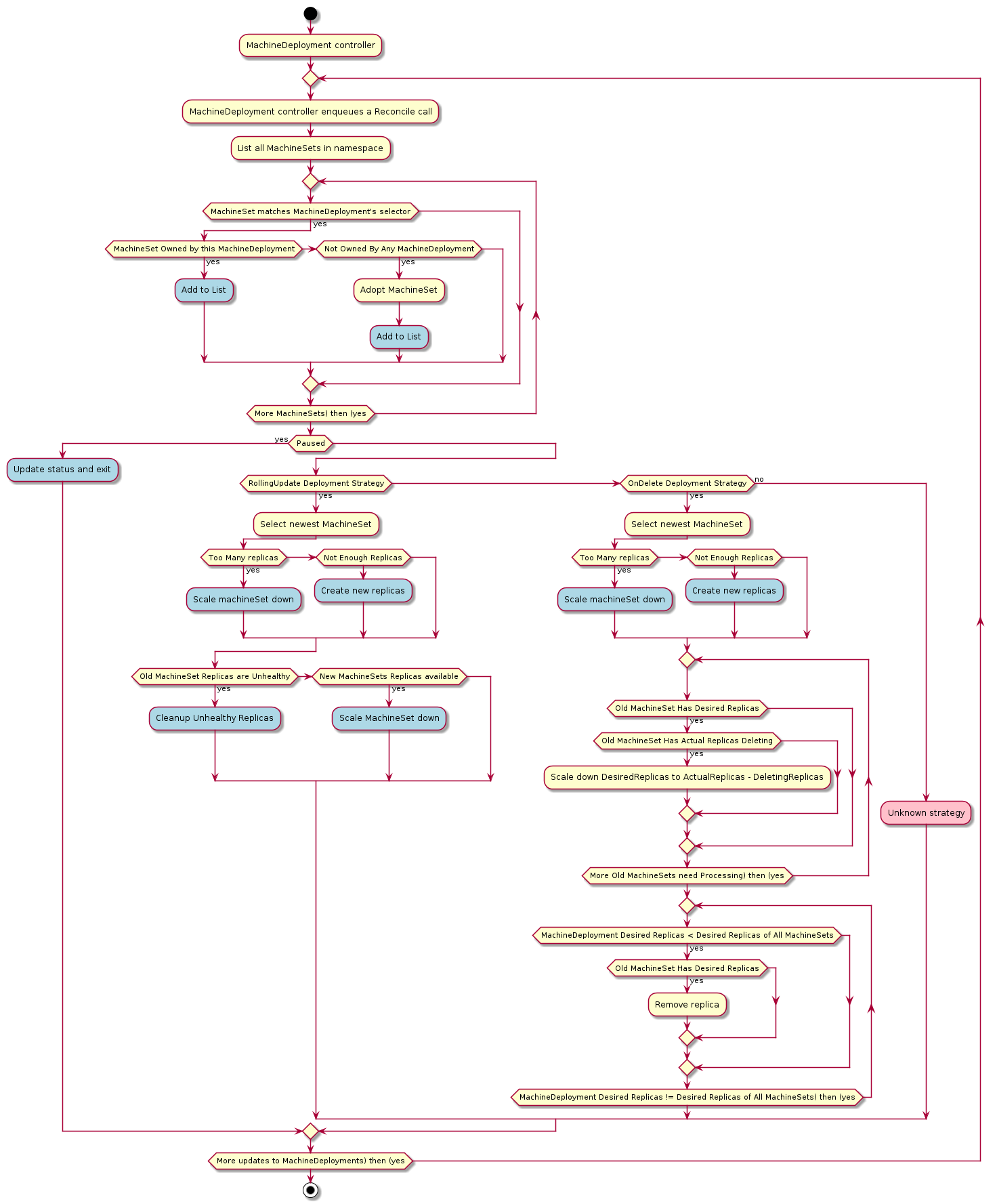
MachineHealthCheck
A MachineHealthCheck is responsible for remediating unhealthy Machines.
Its main responsibilities are:
- Checking the health of Nodes in the workload clusters against a list of unhealthy conditions
- Remediating Machine’s for Nodes determined to be unhealthy
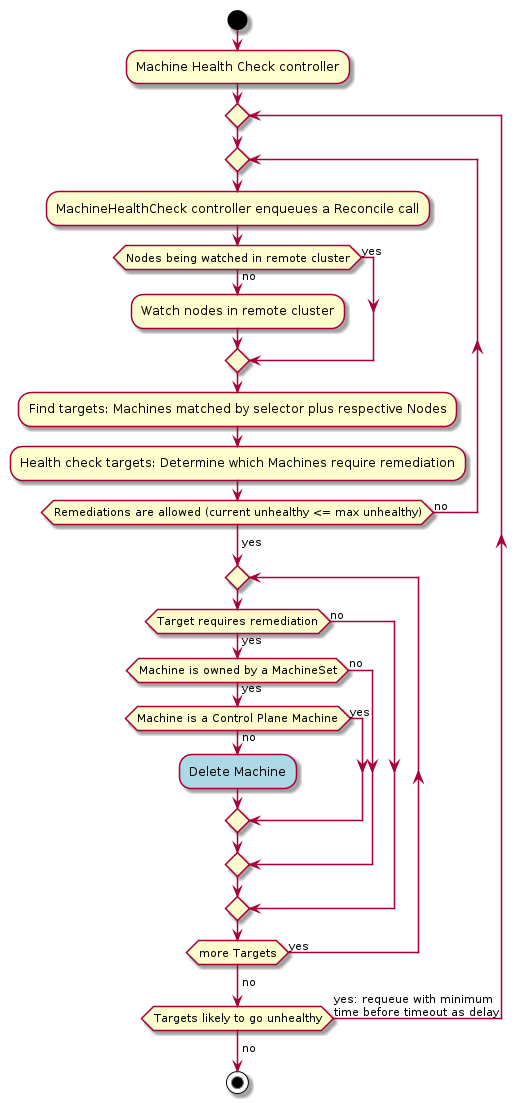
Control Plane Controller
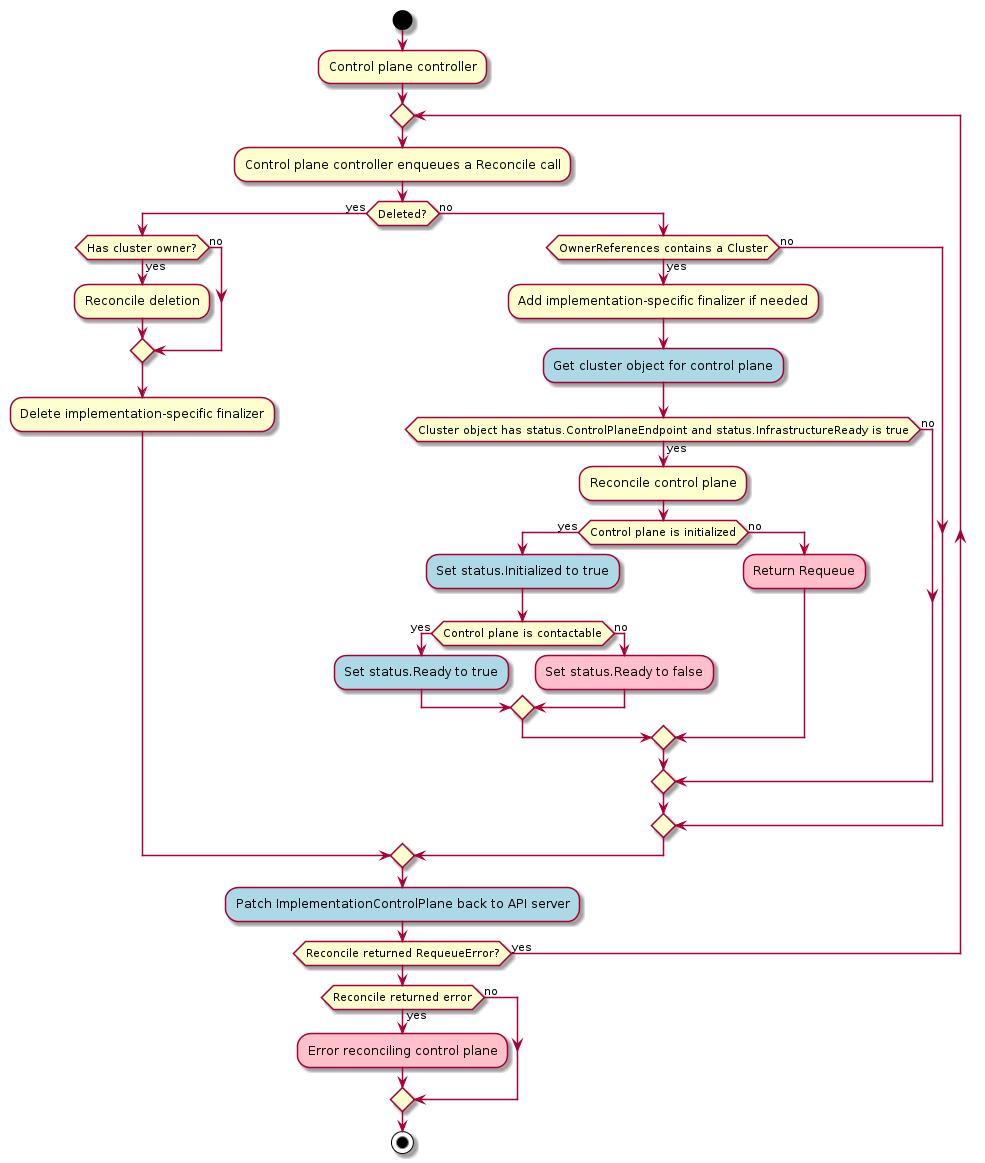
The Control Plane controller’s main responsibilities are:
- Managing a set of machines that represent a Kubernetes control plane.
- Provide information about the state of the control plane to downstream consumers.
- Create/manage a secret with the kubeconfig file for accessing the workload cluster.
A reference implementation is managed within the core Cluster API project as the
Kubeadm control plane controller (KubeadmControlPlane). In this document,
we refer to an example ImplementationControlPlane where not otherwise specified.
Contracts
Control Plane Provider
The general expectation of a control plane controller is to instantiate a Kubernetes control plane consisting of the following services:
Required Control Plane Services
- etcd
- Kubernetes API Server
- Kubernetes Controller Manager
- Kubernetes Scheduler
Optional Control Plane Services
- Cloud controller manager
- Cluster DNS (e.g. CoreDNS)
- Service proxy (e.g. kube-proxy)
Prohibited Services
- CNI - should be left to user to apply once control plane is instantiated.
Relationship to other Cluster API types
The ImplementationControlPlane must rely on the existence of
status.controlplaneEndpoint in its parent Cluster object.
CRD contracts
Required spec fields for implementations using replicas
-
replicas- is an integer representing the number of desired replicas. In the KubeadmControlPlane, this represents the desired number of control plane machines. -
scalesubresource with the following signature:
scale:
labelSelectorPath: .status.selector
specReplicasPath: .spec.replicas
statusReplicasPath: .status.replicas
status: {}
More information about the scale subresource can be found in the Kubernetes documentation.
Required spec fields for implementations using version
version- is a string representing the Kubernetes version to be used by the control plane machines. The value must be a valid semantic version; also if the value provided by the user does not start with the v prefix, it must be added.
Required spec fields for implementations using Machines
-
machineTemplate- is a struct containing details of the control plane machine template. -
machineTemplate.metadata- is a struct containing info about metadata for control plane machines. -
machineTemplate.metadata.labels- is a map of string keys and values that can be used to organize and categorize control plane machines. -
machineTemplate.metadata.annotations- is a map of string keys and values containing arbitrary metadata to be applied to control plane machines. -
machineTemplate.infrastructureRef- is a corev1.ObjectReference to a custom resource offered by an infrastructure provider. The namespace in the ObjectReference must be in the same namespace of the control plane object. -
machineTemplate.nodeDrainTimeout- is a *metav1.Duration defining the total amount of time that the controller will spend on draining a control plane node. The default value is 0, meaning that the node can be drained without any time limitations.
Required status fields
The ImplementationControlPlane object must have a status object.
The status object must have the following fields defined:
| Field | Type | Description | Implementation in Kubeadm Control Plane Controller |
|---|---|---|---|
initialized |
Boolean | a boolean field that is true when the target cluster has completed initialization such that at least once, the target's control plane has been contactable. | Transitions to initialized when the controller detects that kubeadm has uploaded a kubeadm-config configmap, which occurs at the end of kubeadm provisioning. |
ready |
Boolean | Ready denotes that the target API Server is ready to receive requests. |
Required status fields for implementations using replicas
Where the ImplementationControlPlane has a concept of replicas, e.g. most
high availability control planes, then the status object must have the
following fields defined:
| Field | Type | Description | Implementation in Kubeadm Control Plane Controller |
|---|---|---|---|
readyReplicas |
Integer | Total number of fully running and ready control plane instances. | Is equal to the number of fully running and ready control plane machines |
replicas |
Integer | Total number of non-terminated control plane instances, i.e. the state machine for this instance of the control plane is able to transition to ready. | Is equal to the number of non-terminated control plane machines |
selector |
String | `selector` is the label selector in string format to avoid introspection by clients, and is used to provide the CRD-based integration for the scale subresource and additional integrations for things like kubectl describe. The string will be in the same format as the query-param syntax. More info about label selectors: http://kubernetes.io/docs/user-guide/labels#label-selectors | |
unavailableReplicas |
Integer | Total number of unavailable control plane instances targeted by this control plane, equal to the desired number of control plane instances - ready instances. | Total number of unavailable machines targeted by this control plane. This is the total number of machines that are still required for the deployment to have 100% available capacity. They may either be machines that are running but not yet ready or machines that still have not been created. |
updatedReplicas
|
integer | Total number of non-terminated machines targeted by this control plane that have the desired template spec. | Total number of non-terminated machines targeted by this control plane that have the desired template spec. |
Required status fields for implementations using version
version- is a string representing the minimum Kubernetes version for the control plane machines in the cluster. NOTE: The minimum Kubernetes version, and more specifically the API server version, will be used to determine when a control plane is fully upgraded (spec.version == status.version) and for enforcing Kubernetes version skew policies in managed topologies.
Optional status fields
The status object may define several fields:
failureReason- is a string that explains why an error has occurred, if possible.failureMessage- is a string that holds the message contained by the error.externalManagedControlPlane- is a bool that should be set to true if the Node objects do not exist in the cluster. For example, managed control plane providers for AKS, EKS, GKE, etc, should set this totrue. Leaving the field undefined is equivalent to setting the value tofalse.
Example usage
kind: KubeadmControlPlane
apiVersion: cluster.x-k8s.io/v1alpha3
metadata:
name: kcp-1
namespace: default
spec:
infrastructureTemplate:
name: kcp-infra-template
namespace: default
kubeadmConfigSpec:
clusterConfiguration:
version: v1.16.2
Kubeconfig management
Control Plane providers are expected to create and maintain a Kubeconfig secret for operators to gain initial access to the cluster. If a provider uses client certificates for authentication in these Kubeconfigs, the client certificate should be kept with a reasonably short expiration period and periodically regenerated to keep a valid set of credentials available. As an example, the Kubeadm Control Plane provider uses a year of validity and refreshes the certificate after 6 months.
MachinePool Controller
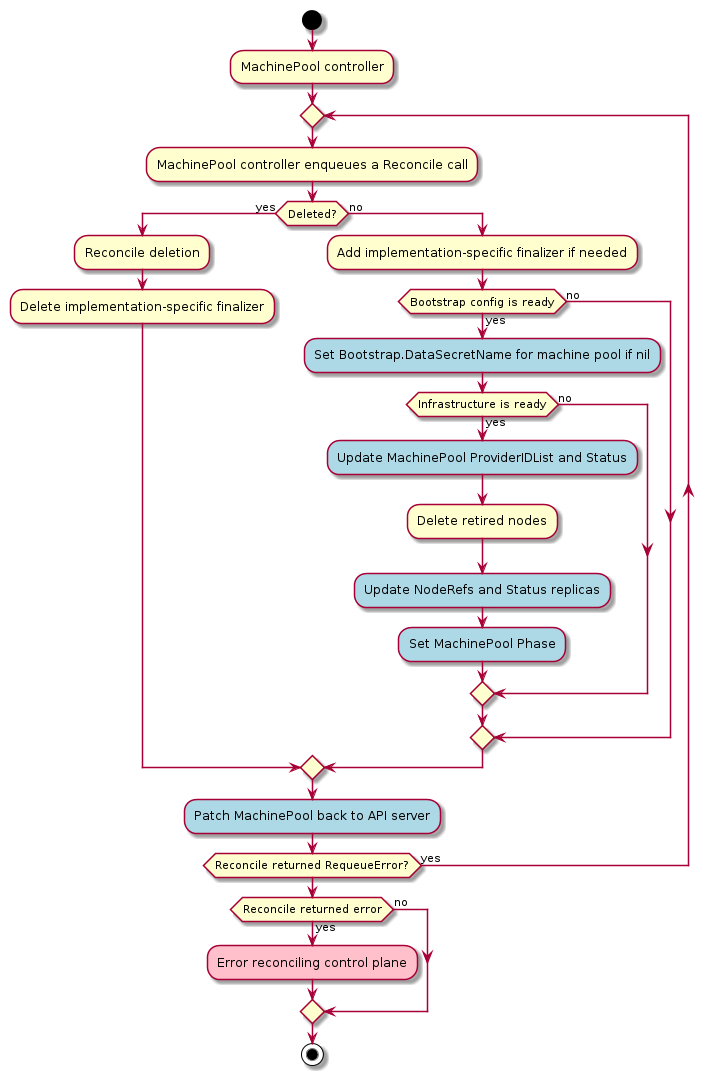
The MachinePool controller’s main responsibilities are:
- Setting an OwnerReference on each MachinePool object to:
- The associated Cluster object.
- The associated BootstrapConfig object.
- The associated InfrastructureMachinePool object.
- Copy data from
BootstrapConfig.Status.DataSecretNametoMachinePool.Spec.Template.Spec.Bootstrap.DataSecretNameifMachinePool.Spec.Template.Spec.Bootstrap.DataSecretNameis empty. - Setting NodeRefs on MachinePool instances to be able to associate them with kubernetes nodes.
- Deleting Nodes in the target cluster when the associated MachinePool instance is deleted.
- Keeping the MachinePool’s Status object up to date with the InfrastructureMachinePool’s Status object.
- Finding Kubernetes nodes matching the expected providerIDs in the workload cluster.
After the machine pool controller sets the OwnerReferences on the associated objects, it waits for the bootstrap
and infrastructure objects referenced by the machine to have the Status.Ready field set to true. When
the infrastructure object is ready, the machine pool controller will attempt to read its Spec.ProviderIDList and
copy it into MachinePool.Spec.ProviderIDList.
The machine pool controller uses the kubeconfig for the new workload cluster to watch new nodes coming up.
When a node appears with a Node.Spec.ProviderID in MachinePool.Spec.ProviderIDList, the machine pool controller
increments the number of ready replicas. When all replicas are ready and the infrastructure ref is also
Ready, the machine pool controller marks the machine pool as Running.
Contracts
Cluster API
Cluster associations are made via labels.
Expected labels
| what | label | value | meaning |
|---|---|---|---|
| MachinePool | cluster.x-k8s.io/cluster-name | <cluster-name> | Identify a machine pool as belonging to a cluster with the name <cluster-name> |
Bootstrap provider
The BootstrapConfig object must have a status object.
To override the bootstrap provider, a user (or external system) can directly set the MachinePool.Spec.Bootstrap.DataSecretName
field. This will mark the machine as ready for bootstrapping and no bootstrap data secret name will be copied from the
BootstrapConfig object.
Required status fields
The status object must have several fields defined:
ready- a boolean field indicating the bootstrap config data is generated and ready for use.dataSecretName- a string field referencing the name of the secret that stores the generated bootstrap data.
Optional status fields
The status object may define several fields that do not affect functionality if missing:
failureReason- a string field explaining why a fatal error has occurred, if possible.failureMessage- a string field that holds the message contained by the error.
Example:
kind: MyBootstrapProviderConfig
apiVersion: bootstrap.cluster.x-k8s.io/v1alpha3
status:
ready: true
dataSecretName: "MyBootstrapSecret"
Infrastructure provider
The InfrastructureMachinePool object must have both spec and status objects.
Required spec fields
The spec object must have at least one field defined:
providerIDList- the list of cloud provider IDs identifying the instances.
Required status fields
The status object must have at least one field defined:
ready- a boolean field indicating if the infrastructure is ready to be used or not.
Optional status fields
The status object may define several fields that do not affect functionality if missing:
failureReason- is a string that explains why a fatal error has occurred, if possible.failureMessage- is a string that holds the message contained by the error.
Example:
kind: MyMachinePool
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3
spec:
providerIDList:
- cloud:////my-cloud-provider-id-0
- cloud:////my-cloud-provider-id-1
status:
ready: true
Secrets
The machine pool controller will use a secret in the following format:
| secret name | field name | content |
|---|---|---|
<cluster-name>-kubeconfig | value | base64 encoded kubeconfig that is authenticated with the workload cluster |
Multi tenancy
Multi tenancy in Cluster API defines the capability of an infrastructure provider to manage different credentials, each one of them corresponding to an infrastructure tenant.
Contract
In order to support multi tenancy, the following rule applies:
- Infrastructure providers MUST be able to manage different sets of credentials (if any)
- Providers SHOULD deploy and run any kind of webhook (validation, admission, conversion) following Cluster API codebase best practices for the same release.
- Providers MUST create and publish a
{type}-component.yamlaccordingly.
Support running multiple instances of the same provider
Up until v1alpha3, the need of supporting multiple credentials was addressed by running multiple instances of the same provider, each one with its own set of credentials while watching different namespaces.
However, running multiple instances of the same provider proved to be complicated for several reasons:
- Complexity in packaging providers: CustomResourceDefinitions (CRD) are global resources, these may have a reference to a service that can be used to convert between CRD versions (conversion webhooks). Only one of these services should be running at any given time, this requirement led us to previously split the webhooks code to a different deployment and namespace.
- Complexity in deploying providers, due to the requirement to ensure consistency of the management cluster, e.g. controllers watching the same namespaces.
- The introduction of the concept of management groups in clusterctl, with impacts on the user experience/documentation.
- Complexity in managing co-existence of different versions of the same provider while there could be only one version of CRDs and webhooks. Please note that this constraint generates a risk, because some version of the provider de-facto were forced to run with CRDs and webhooks deployed from a different version.
Nevertheless, we want to make it possible for users to choose to deploy multiple instances of the same providers, in case the above limitations/extra complexity are acceptable for them.
Contract
In order to make it possible for users to deploy multiple instances of the same provider:
- Providers MUST support the
--namespaceflag in their controllers. - Providers MUST support the
--watch-filterflag in their controllers.
⚠️ Users selecting this deployment model, please be aware:
- Support should be considered best-effort.
- Cluster API (incl. every provider managed under
kubernetes-sigs) won’t release a specialized components file supporting the scenario described above; however, users should be able to create such deployment model from the/configfolder. - Cluster API (incl. every provider managed under
kubernetes-sigs) testing infrastructure won’t run test cases with multiple instances of the same provider.
In conclusion, giving the increasingly complex task that is to manage multiple instances of the same controllers, the Cluster API community may only provide best effort support for users that choose this model.
As always, if some members of the community would like to take on the responsibility of managing this model, please reach out through the usual communication channels, we’ll make sure to guide you in the right path.
Provider Implementers
Cluster API v1alpha1 compared to v1alpha2
Providers
v1alpha1
Providers in v1alpha1 wrap behavior specific to an environment to create the infrastructure and bootstrap instances into Kubernetes nodes. Examples of environments that have integrated with Cluster API v1alpha1 include, AWS, GCP, OpenStack, Azure, vSphere and others. The provider vendors in Cluster API’s controllers, registers its own actuators with the Cluster API controllers and runs a single manager to complete a Cluster API management cluster.
v1alpha2
v1alpha2 introduces two new providers and changes how the Cluster API is consumed. This means that in order to have a complete management cluster that is ready to build clusters you will need three managers.
- Core (Cluster API)
- Bootstrap (kubeadm)
- Infrastructure (aws, gcp, azure, vsphere, etc)
Cluster API’s controllers are no longer vendored by providers. Instead, Cluster API offers its own independent controllers that are responsible for the core types:
- Cluster
- Machine
- MachineSet
- MachineDeployment
Bootstrap providers are an entirely new concept aimed at reducing the amount of kubeadm boilerplate that every provider reimplemented in v1alpha1. The Bootstrap provider is responsible for running a controller that generates data necessary to bootstrap an instance into a Kubernetes node (cloud-init, bash, etc).
v1alpha1 “providers” have become Infrastructure providers. The Infrastructure provider is responsible for generating actual infrastructure (networking, load balancers, instances, etc) for a particular environment that can consume bootstrap data to turn the infrastructure into a Kubernetes cluster.
Actuators
v1alpha1
Actuators are interfaces that the Cluster API controller calls. A provider pulls in the generic Cluster API controller and then registers actuators to run specific infrastructure logic (calls to the provider cloud).
v1alpha2
Actuators are not used in this version. Cluster API’s controllers are no longer shared across providers and therefore they do not need to know about the actuator interface. Instead, providers communicate to each other via Cluster API’s central objects, namely Machine and Cluster. When a user modifies a Machine with a reference, each provider will notice that update and respond in some way. For example, the Bootstrap provider may attach BootstrapData to a BootstrapConfig which will then be attached to the Machine object via Cluster API’s controllers or the Infrastructure provider may create a cloud instance for Kubernetes to run on.
clusterctl
v1alpha1
clusterctl was a command line tool packaged with v1alpha1 providers. The goal of this tool was to go from nothing to a
running management cluster in whatever environment the provider was built for. For example, Cluster-API-Provider-AWS
packaged a clusterctl that created a Kubernetes cluster in EC2 and installed the necessary controllers to respond to
Cluster API’s APIs.
v1alpha2
clusterctl is likely becoming provider-agnostic meaning one clusterctl is bundled with Cluster API and can be reused
across providers. Work here is still being figured out but providers will not be packaging their own clusterctl
anymore.
Cluster API v1alpha2 compared to v1alpha3
Minimum Go version
- The Go version used by Cluster API is now Go 1.13+
In-Tree bootstrap provider
- Cluster API now ships with the Kubeadm Bootstrap provider (CABPK).
- Update import paths from
sigs.k8s.io/cluster-api-bootstrap-provider-kubeadmtosigs.k8s.io/cluster-api/bootstrap/kubeadm.
Machine spec.metadata field has been removed
- The field has been unused for quite some time and didn’t have any function.
- If you have been using this field to setup MachineSet or MachineDeployment, switch to MachineTemplate’s metadata instead.
Set spec.clusterName on Machine, MachineSet, MachineDeployments
- The field is now required on all Cluster dependant objects.
- The
cluster.x-k8s.io/cluster-namelabel is created automatically by each respective controller.
Context is now required for external.CloneTemplate function
- Pass a context as the first argument to calls to
external.CloneTemplate.
Context is now required for external.Get function
- Pass a context as the first argument to calls to
external.Get.
Cluster and Machine Status.Phase field values now start with an uppercase letter
- To be consistent with Pod phases in k/k.
- More details in https://github.com/kubernetes-sigs/cluster-api/pull/1532/files.
MachineClusterLabelName is renamed to ClusterLabelName
- The variable name is renamed as this label isn’t applied to only machines anymore.
- This label is also applied to external objects (bootstrap provider, infrastructure provider)
Cluster and Machine controllers now set cluster.x-k8s.io/cluster-name to external objects
- In addition to the OwnerReference back to the Cluster, a label is now added as well to any external objects, for example objects such as KubeadmConfig (bootstrap provider), AWSCluster (infrastructure provider), AWSMachine (infrastructure provider), etc.
The util/restmapper package has been removed
- Controller runtime has native support for a DynamicRESTMapper, which is used by default when creating a new Manager.
Generated kubeconfig admin username changed from kubernetes-admin to <cluster-name>-admin
- The kubeconfig secret shipped with Cluster API now uses the cluster name as prefix to the
usernamefield.
Changes to sigs.k8s.io/cluster-api/controllers/remote
- The
ClusterClientinterface has been removed. remote.NewClusterClientnow returns asigs.k8s.io/controller-runtime/pkg/clientClient. It also requiresclient.ObjectKeyinstead of a cluster reference. The signature changed:- From:
func NewClusterClient(c client.Client, cluster *clusterv1.Cluster) (ClusterClient, error) - To:
func NewClusterClient(c client.Client, cluster client.ObjectKey, scheme runtime.Scheme) (client.Client, error)
- From:
- Same for the remote client
ClusterClientGetterinterface:- From:
type ClusterClientGetter func(ctx context.Context, c client.Client, cluster *clusterv1.Cluster, scheme *runtime.Scheme) (client.Client, error) - To:
type ClusterClientGetter func(ctx context.Context, c client.Client, cluster client.ObjectKey, scheme *runtime.Scheme) (client.Client, error)
- From:
remote.RESTConfignow usesclient.ObjectKeyinstead of a cluster reference. Signature change:- From:
func RESTConfig(ctx context.Context, c client.Client, cluster *clusterv1.Cluster) (*restclient.Config, error) - To:
func RESTConfig(ctx context.Context, c client.Client, cluster client.ObjectKey) (*restclient.Config, error)
- From:
Related changes to sigs.k8s.io/cluster-api/util
- A helper function
util.ObjectKeycould be used to getclient.ObjectKeyfor a Cluster, Machine etc. - The returned client is no longer configured for lazy discovery. Any consumers that attempt to create a client prior to the server being available will now see an error.
- Getter for a kubeconfig secret, associated with a cluster requires
client.ObjectKeyinstead of a cluster reference. Signature change:- From:
func Get(ctx context.Context, c client.Client, cluster client.ObjectKey, purpose Purpose) (*corev1.Secret, error) - To:
func Get(ctx context.Context, c client.Client, cluster *clusterv1.Cluster, purpose Purpose) (*corev1.Secret, error)
- From:
A Machine is now considered a control plane if it has cluster.x-k8s.io/control-plane set, regardless of value
- Previously examples and tests were setting/checking for the label to be set to
true. - The function
util.IsControlPlaneMachinewas previously checking for any value other than empty string, while now we only check if the associated label exists.
Machine Status.Phase field set to Provisioned if a NodeRef is set but infrastructure is not ready
- The machine Status.Phase is set back to
Provisionedif the infrastructure is not ready. This is only applicable if the infrastructure node status does not have any errors set.
Cluster Status.Phase transition to Provisioned additionally needs at least one APIEndpoint to be available
- Previously, the sole requirement to transition a Cluster’s
Status.PhasetoProvisionedwas atruevalue ofStatus.InfrastructureReady. Now, there are two requirements: atruevalue ofStatus.InfrastructureReadyand at least one entry inStatus.APIEndpoints. - See https://github.com/kubernetes-sigs/cluster-api/pull/1721/files.
Status.ErrorReason and Status.ErrorMessage fields, populated to signal a fatal error has occurred, have been renamed in Cluster, Machine and MachineSet
Status.ErrorReasonhas been renamed toStatus.FailureReasonStatus.ErrorMessagehas been renamed toStatus.FailureMessage
The external.ErrorsFrom function has been renamed to external.FailuresFrom
- The function has been modified to reflect the rename of
Status.ErrorReasontoStatus.FailureReasonandStatus.ErrorMessagetoStatus.FailureMessage.
External objects will need to rename Status.ErrorReason and Status.ErrorMessage
- As a follow up to the changes mentioned above - for the
external.FailuresFromfunction to retain its functionality, external objects (e.g., AWSCluster, AWSMachine, etc.) will need to rename the fields as well. Status.ErrorReasonshould be renamed toStatus.FailureReasonStatus.ErrorMessageshould be renamed toStatus.FailureMessage
The field Cluster.Status.APIEndpoints is removed in favor of Cluster.Spec.ControlPlaneEndpoint
- The slice in Cluster.Status has been removed and replaced by a single APIEndpoint field under Spec.
- Infrastructure providers MUST expose a ControlPlaneEndpoint field in their cluster infrastructure resource at
Spec.ControlPlaneEndpoint. They may optionally remove theStatus.APIEndpointsfield (Cluster API no longer uses it).
Data generated from a bootstrap provider is now stored in a secret
- The Cluster API Machine Controller no longer reconciles the bootstrap provider
status.bootstrapDatafield, but instead looks atstatus.dataSecretName. - The
Machine.Spec.Bootstrap.Datafield is deprecated and will be removed in a future version. - Bootstrap providers must create a Secret in the bootstrap resource’s namespace and store the name in the bootstrap resource’s
status.dataSecretNamefield.- The secret created by the bootstrap provider is of type
cluster.x-k8s.io/secret. - On reconciliation, we suggest to migrate from the deprecated field to a secret reference.
- The secret created by the bootstrap provider is of type
- Infrastructure providers must look for the bootstrap data secret name in
Machine.Spec.Bootstrap.DataSecretNameand fallback toMachine.Spec.Bootstrap.Data.
The cloudinit module under the Kubeadm bootstrap provider has been made private
The cloudinit module has been moved to an internal directory as it is not designed to be a public interface consumed
outside of the existing module.
Interface for Bootstrap Provider Consumers
- Consumers of bootstrap configuration, Machine and eventually MachinePool, must adhere to a
contract that defines a set of required fields used for coordination with the kubeadm bootstrap
provider.
apiVersionto check for supported version/kind.kindto check for supported version/kind.metadata.labels["cluster.x-k8s.io/control-plane"]only present in the case of a control planeMachine.spec.clusterNameto retrieve the owning Cluster status.spec.bootstrap.dataSecretNameto know where to put bootstrap data with sensitive information. Consumers must also verify the secret type matchescluster.x-k8s.io/secret.status.infrastuctureReadyto understand the state of the configuration consumer so the bootstrap provider can take appropriate action (e.g. renew bootstrap token).
Support the cluster.x-k8s.io/paused annotation and Cluster.Spec.Paused field
- A new annotation
cluster.x-k8s.io/pausedprovides the ability to pause reconciliation on specific objects. - A new field
Cluster.Spec.Pausedprovides the ability to pause reconciliation on a Cluster and all associated objects. - A helper function
util.IsPausedcan be used on any Kubernetes object associated with a Cluster and can be used during a Reconcile loop:// Return early if the object or Cluster is paused. if util.IsPaused(cluster, <object>) { logger.Info("Reconciliation is paused for this object") return ctrl.Result{}, nil } - Unless your controller is already watching Clusters, add a Watch to get notifications when Cluster.Spec.Paused field changes.
In most cases,
predicates.ClusterUnpausedandutil.ClusterToObjectsMappercan be used like in the example below:
NB: You need to have// Add a watch on clusterv1.Cluster object for paused notifications. clusterToObjectFunc, err := util.ClusterToObjectsMapper(mgr.GetClient(), <List object here>, mgr.GetScheme()) if err != nil { return err } err = controller.Watch( &source.Kind{Type: &cluserv1.Cluster{}}, &handler.EnqueueRequestsFromMapFunc{ ToRequests: clusterToObjectFunc, }, predicates.ClusterUnpaused(r.Log), ) if err != nil { return err }cluster.x-k8s.io/cluster-nameapplied to all your objects for the mapper to function. - In some cases, you’ll want to not just watch on Cluster.Spec.Paused changes, but also on
Cluster.Status.InfrastructureReady. For those cases
predicates.ClusterUnpausedAndInfrastructureReadyshould be used instead.// Add a watch on clusterv1.Cluster object for paused and infrastructureReady notifications. clusterToObjectFunc, err := util.ClusterToObjectsMapper(mgr.GetClient(), <List object here>, mgr.GetScheme()) if err != nil { return err } err = controller.Watch( &source.Kind{Type: &cluserv1.Cluster{}}, &handler.EnqueueRequestsFromMapFunc{ ToRequests: clusterToObjectFunc, }, predicates.ClusterUnpausedAndInfrastructureReady(r.Log), ) if err != nil { return err }
[OPTIONAL] Support failure domains
An infrastructure provider may or may not implement the failure domains feature. Failure domains gives Cluster API just enough information to spread machines out reducing the risk of a target cluster failing due to a domain outage. This is particularly useful for Control Plane providers. They are now able to put control plane nodes in different domains.
An infrastructure provider can implement this by setting the InfraCluster.Status.FailureDomains field with a map of
unique keys to failureDomainSpecs as well as respecting a set Machine.Spec.FailureDomain field when creating
instances.
To support migration from failure domains that were previously specified through provider-specific resources, the
Machine controller will support updating Machine.Spec.FailureDomain field if Spec.FailureDomain is present and
defined on the provider-defined infrastructure resource.
Please see the cluster and machine infrastructure provider specifications for more detail.
Refactor kustomize config/ folder to support multi-tenancy when using webhooks
Pre-Requisites: Upgrade to CRD v1.
More details and background can be found in Issue #2275 and PR #2279.
Goals:
- Have all webhook related components in the
capi-webhook-systemnamespace.- Achieves multi-tenancy and guarantees that both CRD and webhook resources can live globally and can be patched in future iterations.
- Run a new manager instance that ONLY runs webhooks and doesn’t install any reconcilers.
Steps:
-
In
config/certmanager/- Patch
- certificate.yaml: The
secretNamevalue MUST be set to$(SERVICE_NAME)-cert. - kustomization.yaml: Add the following to
varReference- kind: Certificate group: cert-manager.io path: spec/secretName
- certificate.yaml: The
- Patch
-
In
config/- Create
- kustomization.yaml: This file is going to function as the new entrypoint to run
kustomize build.PROVIDER_NAMEis the name of your provider, e.g.aws.PROVIDER_TYPEis the type of your provider, e.g.control-plane,bootstrap,infrastructure.namePrefix: {{e.g. capa-, capi-, etc.}} commonLabels: cluster.x-k8s.io/provider: "{{PROVIDER_TYPE}}-{{PROVIDER_NAME}}" bases: - crd - webhook # Disable this if you're not using the webhook functionality. - default patchesJson6902: - target: # NOTE: This patch needs to be repeatd for EACH CustomResourceDefinition you have under crd/bases. group: apiextensions.k8s.io version: v1 kind: CustomResourceDefinition name: {{CRD_NAME_HERE}} path: patch_crd_webhook_namespace.yaml - patch_crd_webhook_namespace.yaml: This patch sets the conversion webhook namespace to
capi-webhook-system.- op: replace path: "/spec/conversion/webhook/clientConfig/service/namespace" value: capi-webhook-system
- kustomization.yaml: This file is going to function as the new entrypoint to run
- Create
-
In
config/default- Create
- namespace.yaml
apiVersion: v1 kind: Namespace metadata: name: system
- namespace.yaml
- Move
manager_image_patch.yamltoconfig/managermanager_label_patch.yamltoconfig/managermanager_pull_policy.yamltoconfig/managermanager_auth_proxy_patch.yamltoconfig/managermanager_webhook_patch.yamltoconfig/webhookwebhookcainjection_patch.yamltoconfig/webhookmanager_label_patch.yamlto trash.
- Patch
- kustomization.yaml
- Add under
resources:resources: - namespace.yaml - Replace
baseswith:bases: - ../rbac - ../manager - Add under
patchesStrategicMerge:patchesStrategicMerge: - manager_role_aggregation_patch.yaml - Remove
../crdfrombases(now inconfig/kustomization.yaml). - Remove
namePrefix(now inconfig/kustomization.yaml). - Remove
commonLabels(now inconfig/kustomization.yaml). - Remove from
patchesStrategicMerge:- manager_image_patch.yaml
- manager_pull_policy.yaml
- manager_auth_proxy_patch.yaml
- manager_webhook_patch.yaml
- webhookcainjection_patch.yaml
- manager_label_patch.yaml
- Remove from
vars:- CERTIFICATE_NAMESPACE
- CERTIFICATE_NAME
- SERVICE_NAMESPACE
- SERVICE_NAME
- Add under
- kustomization.yaml
- Create
-
In
config/manager- Patch
- manager.yaml: Remove the
Namespaceobject. - kustomization.yaml:
- Add under
patchesStrategicMerge:patchesStrategicMerge: - manager_image_patch.yaml - manager_pull_policy.yaml - manager_auth_proxy_patch.yaml
- Add under
- manager.yaml: Remove the
- Patch
-
In
config/webhook- Patch
- kustomizeconfig.yaml
- Add the following to
varReference- kind: Deployment path: spec/template/spec/volumes/secret/secretName
- Add the following to
- kustomization.yaml
- Add
namespace: capi-webhook-systemat the top of the file. - Under
resources, add../certmanagerand../manager. - Add at the bottom of the file:
patchesStrategicMerge: - manager_webhook_patch.yaml - webhookcainjection_patch.yaml # Disable this value if you don't have any defaulting or validation webhook. If you don't know, you can check if the manifests.yaml file in the same directory has any contents. vars: - name: CERTIFICATE_NAMESPACE # namespace of the certificate CR objref: kind: Certificate group: cert-manager.io version: v1alpha2 name: serving-cert # this name should match the one in certificate.yaml fieldref: fieldpath: metadata.namespace - name: CERTIFICATE_NAME objref: kind: Certificate group: cert-manager.io version: v1alpha2 name: serving-cert # this name should match the one in certificate.yaml - name: SERVICE_NAMESPACE # namespace of the service objref: kind: Service version: v1 name: webhook-service fieldref: fieldpath: metadata.namespace - name: SERVICE_NAME objref: kind: Service version: v1 name: webhook-service
- Add
- manager_webhook_patch.yaml
- Under
containersfindmanagerand add aftername- "--metrics-bind-addr=127.0.0.1:8080" - "--webhook-port=9443" - Under
volumesfindcertand replacesecretName‘s value with$(SERVICE_NAME)-cert.
- Under
- service.yaml
- Remove the
selectormap, if any. Thecontrol-planelabel is not needed anymore, a unique label is applied usingcommonLabelsunderconfig/kustomization.yaml.
- Remove the
- kustomizeconfig.yaml
- Patch
In main.go
- Default the
webhook-portflag to0flag.IntVar(&webhookPort, "webhook-port", 0, "Webhook Server port, disabled by default. When enabled, the manager will only work as webhook server, no reconcilers are installed.") - The controller MUST register reconcilers if and only if
webhookPort == 0. - The controller MUST register webhooks if and only if
webhookPort != 0.
After all the changes above are performed, kustomize build MUST target config/, rather than config/default. Using your favorite editor, search for config/default in your repository and change the paths accordingly.
In addition, often the Makefile contains a sed-replacement for manager_image_patch.yaml, this file has been moved from config/default to config/manager. Using your favorite editor, search for manager_image_patch in your repository and change the paths accordingly.
Apply the contract version label cluster.x-k8s.io/<version>: version1_version2_version3 to your CRDs
- Providers MUST set
cluster.x-k8s.io/<version>labels on all Custom Resource Definitions related to Cluster API starting with v1alpha3. - The label is a map from an API Version of Cluster API (contract) to your Custom Resource Definition versions.
- The value is a underscore-delimited (
_) list of versions. - Each value MUST point to an available version in your CRD Spec.
- The value is a underscore-delimited (
- The label allows Cluster API controllers to perform automatic conversions for object references, the controllers will pick the last available version in the list if multiple versions are found.
- To apply the label to CRDs it’s possible to use
commonLabelsin yourkustomize.yamlfile, usually inconfig/crd.
In this example we show how to map a particular Cluster API contract version to your own CRD using Kustomize’s commonLabels feature:
commonLabels:
cluster.x-k8s.io/v1alpha2: v1alpha1
cluster.x-k8s.io/v1alpha3: v1alpha2
cluster.x-k8s.io/v1beta1: v1alphaX_v1beta1
Upgrade to CRD v1
- Providers should upgrade their CRDs to v1
- Minimum Kubernetes version supporting CRDv1 is
v1.16 - In
Makefiletargetgenerate-manifests:, add the following property to the crdcrdVersions=v1
generate-manifests: $(CONTROLLER_GEN) ## Generate manifests e.g. CRD, RBAC etc.
$(CONTROLLER_GEN) \
paths=./api/... \
crd:crdVersions=v1 \
output:crd:dir=$(CRD_ROOT) \
output:webhook:dir=$(WEBHOOK_ROOT) \
webhook
$(CONTROLLER_GEN) \
paths=./controllers/... \
output:rbac:dir=$(RBAC_ROOT) \
rbac:roleName=manager-role
- For all the CRDs in the
config/crd/baseschange the version ofCustomResourceDefinitiontov1
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
to
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
- In the
config/crd/kustomizeconfig.yamlfile, change the path of the webhook
path: spec/conversion/webhookClientConfig/service/name
to
spec/conversion/webhook/clientConfig/service/name
- Make the same change of changing
v1betatov1version in theconfig/crd/patches - In the
config/crd/patches/webhook_in_******.yamlfile, add theconversionReviewVersionsproperty to the CRD
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
...
spec:
conversion:
strategy: Webhook
webhookClientConfig:
...
to
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
...
spec:
strategy: Webhook
webhook:
conversionReviewVersions: ["v1", "v1beta1"]
clientConfig:
...
Add matchPolicy=Equivalent kubebuilder marker in webhooks
- All providers should set “matchPolicy=Equivalent” kubebuilder marker for webhooks on all Custom Resource Definitions related to Cluster API starting with v1alpha3.
- Specifying
Equivalentensures that webhooks continue to intercept the resources they expect when upgrades enable new versions of the resource in the API server. - E.g.,
matchPolicyis added toAWSMachine(/api/v1alpha3/awsmachine_webhook.go)// +kubebuilder:webhook:verbs=create;update,path=/validate-infrastructure-cluster-x-k8s-io-v1alpha3-awsmachine,mutating=false,failurePolicy=fail,matchPolicy=Equivalent,groups=infrastructure.cluster.x-k8s.io,resources=awsmachines,versions=v1alpha3,name=validation.awsmachine.infrastructure.cluster.x-k8s.io - Support for
matchPolicymarker has been added in kubernetes-sigs/controller-tools. Providers needs to update controller-tools dependency to make use of it, usually inhack/tools/go.mod.
[OPTIONAL] Implement --feature-gates flag in main.go
- Cluster API now ships with a new experimental package that lives under
exp/containing both API types and controllers. - Controller and types should always live behind a gate defined under the
feature/package. - If you’re planning to support experimental features or API types in your provider or codebase, you can add
feature.MutableGates.AddFlag(fs)to your main.go when initializing command line flags. For a full example, you can refer to themain.goin Cluster API or underbootstrap/kubeadm/.
NOTE: To enable experimental features users are required to set the same
--feature-gatesflag across providers. For example, if you want to enable MachinePool, you’ll have to enable in both Cluster API deployment and the Kubeadm Bootstrap Provider. In the future, we’ll revisit this user experience and provide a centralized way to configure gates across all Cluster API (inc. providers) controllers.
clusterctl
clusterctl is now bundled with Cluster API, provider-agnostic and can be reused across providers.
It is the recommended way to setup a management cluster and it implements best practices to avoid common mis-configurations
and for managing the life-cycle of deployed providers, e.g. upgrades.
see clusterctl provider contract for more details.
Cluster API v1alpha3 compared to v1alpha4
Minimum Go version
- The Go version used by Cluster API is now Go 1.16+
- In case cloudbuild is used to push images, please upgrade to
gcr.io/k8s-testimages/gcb-docker-gcloud:v20210331-c732583in the cloudbuild YAML files.
- In case cloudbuild is used to push images, please upgrade to
Controller Runtime version
- The Controller Runtime version is now v0.9.+
Controller Tools version (if used)
- The Controller Tools version is now v0.6.+
Kind version
- The KIND version used for this release is v0.11.x
:warning: Go Module changes :warning:
- The
testfolder now ships with its own Go modulesigs.k8s.io/cluster-api/test. - The module is going to be tagged and versioned as part of the release.
- Folks importing the test e2e framework or the docker infrastructure provider need to import the new module.
- When imported, the test module version should always match the Cluster API one.
- Add the following line in
go.modto replace the cluster-api dependency in the test module (change the version to your current Cluster API version):
replace sigs.k8s.io/cluster-api => sigs.k8s.io/cluster-api v0.4.x - The CAPD go module in test/infrastructure/docker has been removed.
Klog version
-
The klog package used has been upgraded to v2.5.x. It is recommended that all providers also switch to using v2.
- Change
import k8s.io/klogtoimport k8s.io/klog/v2 - Change
import k8s.io/klog/klogrtoimport k8s.io/klog/v2/klogr - Update
go.modtok8s.io/klog/v2 v2.5.0 - Run
go mod tidyto ensure all dependencies are updated.
- Change
The controllers.DeleteNodeAnnotation constant has been removed
- This annotation
cluster.k8s.io/delete-machinewas originally deprecated a while ago when we moved our types under thex-k8s.iodomain.
The controllers.DeleteMachineAnnotation has been moved to v1alpha4.DeleteMachineAnnotation
- This annotation was previously exported as part of the controllers package, instead this should be a versioned annotation under the api packages.
Align manager flag names with upstream Kubernetes components
- Rename
--metrics-addrto--metrics-bind-addr - Rename
--leader-electionto--leader-elect
util.ManagerDelegatingClientFunc has been removed
This function was originally used to generate a delegating client when creating a new manager.
Controller Runtime v0.9.x now uses a ClientBuilder in its Options struct and it uses
the delegating client by default under the hood, so this can be now removed.
Use to Controller Runtime’s new fake client builder
- The functions
fake.NewFakeClientWithSchemeandfake.NewFakeClienthave been deprecated. - Switch to
fake.NewClientBuilder().WithObjects().Build()instead, which provides a cleaner interface to create a new fake client with objects, lists, or a scheme.
Multi tenancy
Up until v1alpha3, the need of supporting multiple credentials was addressed by running multiple instances of the same provider, each one with its own set of credentials while watching different namespaces.
Starting from v1alpha4 instead we are going require that an infrastructure provider should manage different credentials, each one of them corresponding to an infrastructure tenant.
see Multi-tenancy and Support multiple instances for more details.
Specific changes related to this topic will be detailed in this document.
Change types with arrays of pointers to custom objects
The conversion-gen code from the 1.20.x release onward generates incorrect conversion functions for types having arrays of pointers to custom objects. Change the existing types to contain objects instead of pointer references.
Optional flag for specifying webhook certificates dir
Add optional flag --webhook-cert-dir={string-value} which allows user to specify directory where webhooks will get tls certificates.
If flag has not provided, default value from controller-runtime should be used.
Required kustomize changes to have a single manager watching all namespaces and answer to webhook calls
In an effort to simplify the management of Cluster API components, and realign with Kubebuilder configuration,
we’re requiring some changes to move all webhooks back into a single deployment manager, and to allow Cluster
API watch all namespaces it manages.
For a /config folder reference, please use the testdata in the Kubebuilder project: https://github.com/kubernetes-sigs/kubebuilder/tree/master/testdata/project-v3/config
Pre-requisites
Provider’s /config folder has the same structure of /config folder in CAPI controllers.
Changes in the /config/webhook folder:
- Edit the
/config/webhook/kustomization.yamlfile:- Remove the
namespace:configuration - In the
resources:list, remove the following items:- ../certmanager - ../manager - Remove the
patchesStrategicMergelist - Copy the
varslist into a temporary file to be used later in the process - Remove the
varslist
- Remove the
- Edit the
config/webhook/kustomizeconfig.yamlfile:- In the
varReference:list, remove the item withkind: Deployment
- In the
- Edit the
/config/webhook/manager_webhook_patch.yamlfile and remove theargslist from themanagercontainer. - Move the following files to the
/config/defaultfolder/config/webhook/manager_webhook_patch.yaml/config/webhook/webhookcainjection_patch.yaml
Changes in the /config/manager folder:
- Edit the
/config/manager/kustomization.yamlfile:- Remove the
patchesStrategicMergelist
- Remove the
- Edit the
/config/manager/manager.yamlfile:- Add the following items to the
argslist for themanagercontainer list
- "--metrics-bind-addr=127.0.0.1:8080"- Verify that feature flags required by your container are properly set
(as it was in
/config/webhook/manager_webhook_patch.yaml).
- Add the following items to the
- Edit the
/config/manager/manager_auth_proxy_patch.yamlfile:- Remove the patch for the container with name
manager
- Remove the patch for the container with name
- Move the following files to the
/config/defaultfolder/config/manager/manager_auth_proxy_patch.yaml/config/manager/manager_image_patch.yaml/config/manager/manager_pull_policy.yaml
Changes in the /config/default folder:
- Create a file named
/config/default/kustomizeconfig.yamlwith the following content:# This configuration is for teaching kustomize how to update name ref and var substitution varReference: - kind: Deployment path: spec/template/spec/volumes/secret/secretName - Edit the
/config/default/kustomization.yamlfile:- Add the
namePrefixand thecommonLabelsconfiguration values copying values from the/config/kustomization.yamlfile - In the
bases:list, add the following items:- ../crd - ../certmanager - ../webhook - Add the
patchesStrategicMerge:list, with the following items:- manager_auth_proxy_patch.yaml - manager_image_patch.yaml - manager_pull_policy.yaml - manager_webhook_patch.yaml - webhookcainjection_patch.yaml - Add a
vars:configuration using the value from the temporary file created while modifying/config/webhook/kustomization.yaml - Add the
configurations:list with the following items:- kustomizeconfig.yaml
- Add the
Changes in the /config folder:
- Remove the
/config/kustomization.yamlfile - Remove the
/config/patch_crd_webhook_namespace.yamlfile
Changes in the main.go file:
- Change default value for the flags
webhook-portflag to9443 - Change your code so all the controllers and the webhooks are started no matter if the webhooks port selected.
Other changes:
- makefile
- update all the references for
/config/manager/manager_image_patch.yamlto/config/default/manager_image_patch.yaml - update all the references for
/config/manager/manager_pull_policy.yamlto/config/default/manager_pull_policy.yaml - update all the call to
kustomizetargeting/configto target/config/defaultinstead.
- update all the references for
- E2E config files
- update provider sources reading from
/configto read from/config/defaultinstead.
- update provider sources reading from
- clusterctl-settings.json file
- if the
configFoldervalue is defined, update from/configto/config/default.
- if the
Upgrade cert-manager to v1.1.0
NB. instructions assumes “Required kustomize changes to have a single manager watching all namespaces and answer to webhook calls” should be executed before this changes.
Changes in the /config/certmanager folder:
- Edit the
/config/certmanager/certificate.yamlfile and replace all the occurrences ofcert-manager.io/v1alpha2withcert-manager.io/v1
Changes in the /config/default folder:
- Edit the
/config/default/kustomization.yamlfile and replace all the occurencies of
withkind: Certificate group: cert-manager.io version: v1alpha2kind: Certificate group: cert-manager.io version: v1
Support the cluster.x-k8s.io/watch-filter label and watch-filter flag.
- A new label
cluster.x-k8s.io/watch-filterprovides the ability to filter the controllers to only reconcile objects with a specific label. - A new flag
watch-filterenables users to specify the label value for thecluster.x-k8s.io/watch-filterlabel on controller boot. - The flag which enables users to set the flag value can be structured like this:
fs.StringVar(&watchFilterValue, "watch-filter", "", fmt.Sprintf("Label value that the controller watches to reconcile cluster-api objects. Label key is always %s. If unspecified, the controller watches for all cluster-api objects.", clusterv1.WatchLabel)) - The
ResourceNotPausedAndHasFilterLabelpredicate is a useful helper to check for the pause annotation and the filter label easily:c, err := ctrl.NewControllerManagedBy(mgr). For(&clusterv1.MachineSet{}). Owns(&clusterv1.Machine{}). Watches( &source.Kind{Type: &clusterv1.Machine{}}, handler.EnqueueRequestsFromMapFunc(r.MachineToMachineSets), ). WithOptions(options). WithEventFilter(predicates.ResourceNotPausedAndHasFilterLabel(ctrl.LoggerFrom(ctx), r.WatchFilterValue)). Build(r) if err != nil { return errors.Wrap(err, "failed setting up with a controller manager") }
Required changes to have individual service accounts for controllers.
- Create a new service account such as:
apiVersion: v1
kind: ServiceAccount
metadata:
name: manager
namespace: system
- Change the
subjectof the managersClusterRoleBindingto match:
subjects:
- kind: ServiceAccount
name: manager
namespace: system
- Add the correct
serviceAccountNameto the manager deployment:
serviceAccountName: manager
Percentage String or Int API input will fail with a string different from an integer with % appended.
MachineDeployment.Spec.Strategy.RollingUpdate.MaxSurge, MachineDeployment.Spec.Strategy.RollingUpdate.MaxUnavailable and MachineHealthCheck.Spec.MaxUnhealthy would have previously taken a String value with an integer character in it e.g “3” as a valid input and process it as a percentage value.
Only String values like “3%” or Int values e.g 3 are valid input values now. A string not matching the percentage format will fail, e.g “3”.
Required change to support externally managed infrastructure.
- A new annotation
cluster.x-k8s.io/managed-byhas been introduced that allows cluster infrastructure to be managed externally. - When this annotation is added to an
InfraClusterresource, the controller for these resources should not reconcile the resource. - The
ResourceIsNotExternallyManagedpredicate is a useful helper to check for the annotation and the filter the resource easily:c, err := ctrl.NewControllerManagedBy(mgr). For(&providerv1.InfraCluster{}). Watches(...). WithOptions(options). WithEventFilter(predicates.ResourceIsNotExternallyManaged(ctrl.LoggerFrom(ctx))). Build(r) if err != nil { return errors.Wrap(err, "failed setting up with a controller manager") } - Note: this annotation also has to be checked in other cases, e.g. when watching for the Cluster resource.
MachinePool API group changed to cluster.x-k8s.io
MachinePool is today an experiment, and the API group we originally decided to pick was exp.cluster.x-k8s.io. Given that the intent is in the future to move MachinePool to the core API group, we changed the experiment to use cluster.x-k8s.io group to avoid future breaking changes.
All InfraMachinePool implementations should be moved to infrastructure.cluster.x-k8s.io. See DockerMachinePool for an example.
Note that MachinePools are still experimental after this change and should still be feature gated.
Golangci-lint configuration
There were a lot of new useful linters added to .golangci.yml. Of course it’s not mandatory to use golangci-lint or
a similar configuration, but it might make sense regardless. Please note there was previously an error in
the exclude configuration which has been fixed in #4657. As
this configuration has been duplicated in a few other providers, it could be that you’re also affected.
test/helpers.NewFakeClientWithScheme has been removed
This function used to create a new fake client with the given scheme for testing, and all the objects given as input were initialized with a resource version of “1”. The behavior of having a resource version in fake client has been fixed in controller-runtime, and this function isn’t needed anymore.
Required kustomize changes to remove Kubeadm-rbac-proxy
NB. instructions assumes “Required kustomize changes to have a single manager watching all namespaces and answer to webhook calls” should be executed before this changes.
Changes in the /config/default folder:
- Edit
/config/default/kustomization.yamland remove themanager_auth_proxy_patch.yamlitem from thepatchesStrategicMergelist. - Delete the
/config/default/manager_auth_proxy_patch.yamlfile.
Changes in the /config/manager folder:
- Edit
/config/manager/manager.yamland remove the--metrics-bind-addr=127.0.0.1:8080arg from theargslist.
Changes in the /config/rbac folder:
- Edit
/config/rbac/kustomization.yamland remove following items from theresourceslist.auth_proxy_service.yamlauth_proxy_role.yamlauth_proxy_role_binding.yaml
- Delete the
/config/rbac/auth_proxy_service.yamlfile. - Delete the
/config/rbac/auth_proxy_role.yamlfile. - Delete the
/config/rbac/auth_proxy_role_binding.yamlfile.
Changes in the main.go file:
- Change the default value for the
metrics-bind-addrfrom:8080tolocalhost:8080
Required cluster template changes
spec.infrastructureTemplatehas been moved tospec.machineTemplate.infrastructureRef. Thus, cluster templates which includeKubeadmControlPlanehave to be adjusted accordingly.spec.nodeDrainTimeouthas been moved tospec.machineTemplate.nodeDrainTimeout.
Cluster Infrastructure Provider Specification
Overview
A cluster infrastructure provider supplies whatever prerequisites are necessary for running machines. Examples might include networking, load balancers, firewall rules, and so on.
Data Types
A cluster infrastructure provider must define an API type for “infrastructure cluster” resources. The type:
- Must belong to an API group served by the Kubernetes apiserver
- May be implemented as a CustomResourceDefinition, or as part of an aggregated apiserver
- Must be namespace-scoped
- Must have the standard Kubernetes “type metadata” and “object metadata”
- Must have a
specfield with the following:- Required fields:
controlPlaneEndpoint(apiEndpoint): the endpoint for the cluster’s control plane.apiEndpointis defined as:host(string): DNS name or IP addressport(int32): TCP port
- Required fields:
- Must have a
statusfield with the following:- Required fields:
ready(boolean): indicates the provider-specific infrastructure has been provisioned and is ready
- Optional fields:
failureReason(string): indicates there is a fatal problem reconciling the provider’s infrastructure; meant to be suitable for programmatic interpretationfailureMessage(string): indicates there is a fatal problem reconciling the provider’s infrastructure; meant to be a more descriptive value thanfailureReasonfailureDomains(failureDomains): the failure domains that machines should be placed in.failureDomainsis a map, defined asmap[string]FailureDomainSpec. A unique key must be used for eachFailureDomainSpec.FailureDomainSpecis defined as:controlPlane(bool): indicates if failure domain is appropriate for running control plane instances.attributes(map[string]string): arbitrary attributes for users to apply to a failure domain.
- Required fields:
Behavior
A cluster infrastructure provider must respond to changes to its “infrastructure cluster” resources. This process is typically called reconciliation. The provider must watch for new, updated, and deleted resources and respond accordingly.
The following diagram shows the typical logic for a cluster infrastructure provider:
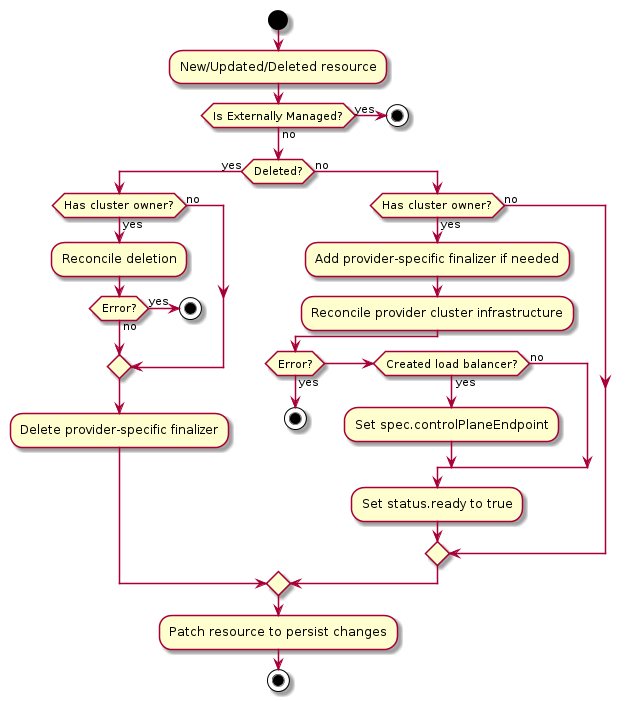
Normal resource
- If the resource is externally managed, exit the reconciliation
- The
ResourceIsNotExternallyManagedpredicate can be used to prevent reconciling externally managed resources
- The
- If the resource does not have a
Clusterowner, exit the reconciliation- The Cluster API
Clusterreconciler populates this based on the value in theCluster‘sspec.infrastructureReffield.
- The Cluster API
- Add the provider-specific finalizer, if needed
- Reconcile provider-specific cluster infrastructure
- If any errors are encountered, exit the reconciliation
- If the provider created a load balancer for the control plane, record its hostname or IP in
spec.controlPlaneEndpoint - Set
status.readytotrue - Set
status.failureDomainsbased on available provider failure domains (optional) - Patch the resource to persist changes
Deleted resource
- If the resource has a
Clusterowner- Perform deletion of provider-specific cluster infrastructure
- If any errors are encountered, exit the reconciliation
- Remove the provider-specific finalizer from the resource
- Patch the resource to persist changes
RBAC
Provider controller
A cluster infrastructure provider must have RBAC permissions for the types it defines. If you are using kubebuilder to
generate new API types, these permissions should be configured for you automatically. For example, the AWS provider has
the following configuration for its AWSCluster type:
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=awsclusters,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=awsclusters/status,verbs=get;update;patch
A cluster infrastructure provider may also need RBAC permissions for other types, such as Cluster. If you need
read-only access, you can limit the permissions to get, list, and watch. The AWS provider has the following
configuration for retrieving Cluster resources:
// +kubebuilder:rbac:groups=cluster.x-k8s.io,resources=clusters;clusters/status,verbs=get;list;watch
Cluster API controllers
The Cluster API controller for Cluster resources is configured with full read/write RBAC
permissions for all resources in the infrastructure.cluster.x-k8s.io API group. This group
represents all cluster infrastructure providers for SIG Cluster Lifecycle-sponsored provider
subprojects. If you are writing a provider not sponsored by the SIG, you must grant full read/write
RBAC permissions for the “infrastructure cluster” resource in your API group to the Cluster API
manager’s ServiceAccount. ClusterRoles can be granted using the aggregation label
cluster.x-k8s.io/aggregate-to-manager: "true". The following is an example ClusterRole for a
FooCluster resource:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: capi-foo-clusters
labels:
cluster.x-k8s.io/aggregate-to-manager: "true"
rules:
- apiGroups:
- infrastructure.foo.com
resources:
- fooclusters
verbs:
- create
- delete
- get
- list
- patch
- update
- watch
Note, the write permissions allow the Cluster controller to set owner references and labels on the
“infrastructure cluster” resources; they are not used for general mutations of these resources.
Machine Infrastructure Provider Specification
Overview
A machine infrastructure provider is responsible for managing the lifecycle of provider-specific machine instances. These may be physical or virtual instances, and they represent the infrastructure for Kubernetes nodes.
Data Types
A machine infrastructure provider must define an API type for “infrastructure machine” resources. The type:
- Must belong to an API group served by the Kubernetes apiserver
- May be implemented as a CustomResourceDefinition, or as part of an aggregated apiserver
- Must be namespace-scoped
- Must have the standard Kubernetes “type metadata” and “object metadata”
- Must have a
specfield with the following:- Required fields:
providerID(string): the identifier for the provider’s machine instance
- Optional fields:
failureDomain(string): the string identifier of the failure domain the instance is running in for the purposes of backwards compatibility and migrating to the v1alpha3 FailureDomain support (where FailureDomain is specified in Machine.Spec.FailureDomain). This field is meant to be temporary to aid in migration of data that was previously defined on the provider type and providers will be expected to remove the field in the next version that provides breaking API changes, favoring the value defined on Machine.Spec.FailureDomain instead. If supporting conversions from previous types, the provider will need to support a conversion from the provider-specific field that was previously used to thefailureDomainfield to support the automated migration path.
- Required fields:
- Must have a
statusfield with the following:- Required fields:
ready(boolean): indicates the provider-specific infrastructure has been provisioned and is ready
- Optional fields:
failureReason(string): indicates there is a fatal problem reconciling the provider’s infrastructure; meant to be suitable for programmatic interpretationfailureMessage(string): indicates there is a fatal problem reconciling the provider’s infrastructure; meant to be a more descriptive value thanfailureReasonaddresses(MachineAddress): a list of the host names, external IP addresses, internal IP addresses, external DNS names, and/or internal DNS names for the provider’s machine instance.MachineAddressis defined as: -type(string): one ofHostname,ExternalIP,InternalIP,ExternalDNS,InternalDNS-address(string)
- Required fields:
Behavior
A machine infrastructure provider must respond to changes to its “infrastructure machine” resources. This process is typically called reconciliation. The provider must watch for new, updated, and deleted resources and respond accordingly.
The following diagram shows the typical logic for a machine infrastructure provider:
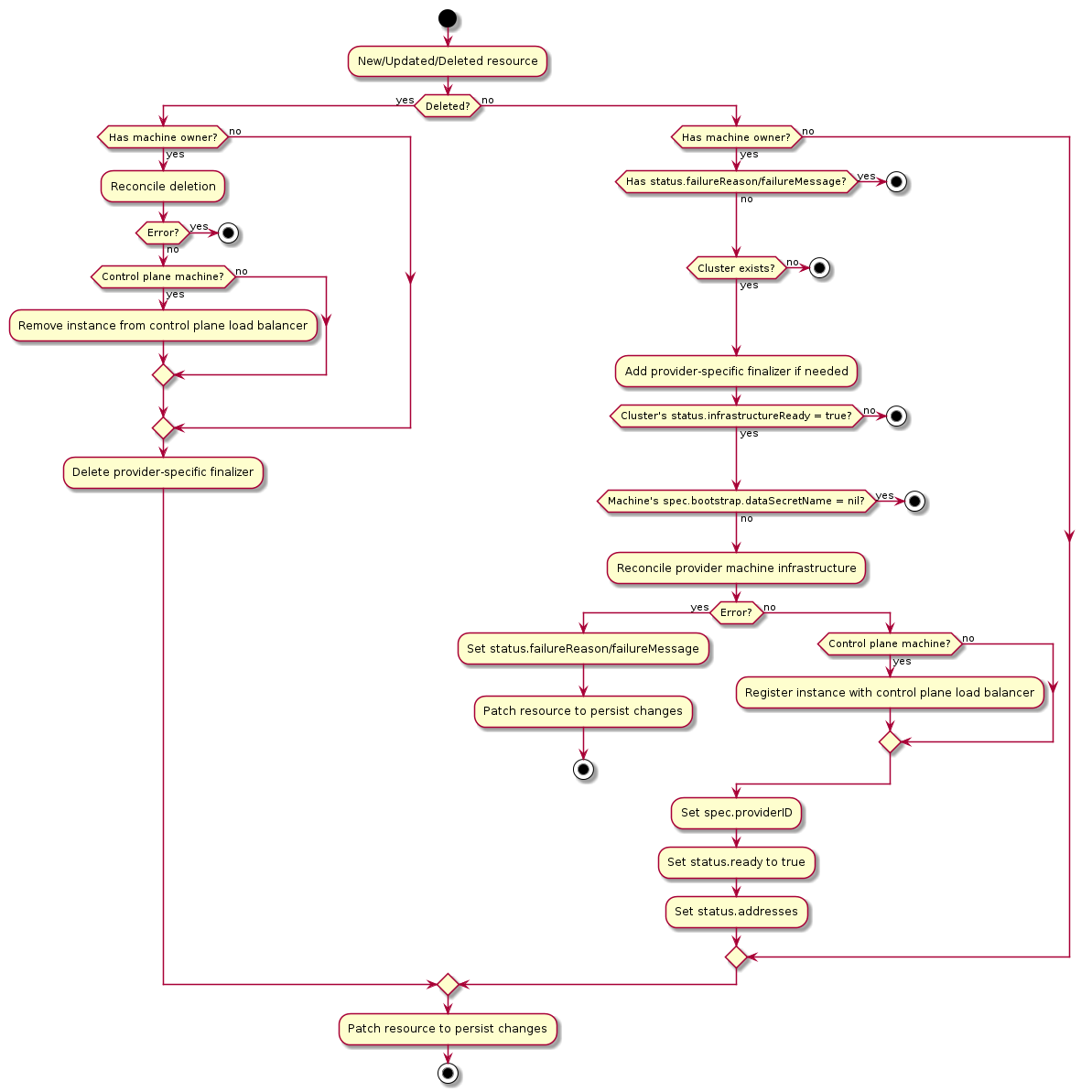
Normal resource
- If the resource does not have a
Machineowner, exit the reconciliation- The Cluster API
Machinereconciler populates this based on the value in theMachines‘sspec.infrastructureReffield
- The Cluster API
- If the resource has
status.failureReasonorstatus.failureMessageset, exit the reconciliation - If the
Clusterto which this resource belongs cannot be found, exit the reconciliation - Add the provider-specific finalizer, if needed
- If the associated
Cluster‘sstatus.infrastructureReadyisfalse, exit the reconciliation - If the associated
Machine‘sspec.bootstrap.dataSecretNameisnil, exit the reconciliation - Reconcile provider-specific machine infrastructure
- If any errors are encountered:
- If they are terminal failures, set
status.failureReasonandstatus.failureMessage - Exit the reconciliation
- If they are terminal failures, set
- If this is a control plane machine, register the instance with the provider’s control plane load balancer (optional)
- If any errors are encountered:
- Set
spec.providerIDto the provider-specific identifier for the provider’s machine instance - Set
status.readytotrue - Set
status.addressesto the provider-specific set of instance addresses (optional) - Set
spec.failureDomainto the provider-specific failure domain the instance is running in (optional) - Patch the resource to persist changes
Deleted resource
- If the resource has a
Machineowner- Perform deletion of provider-specific machine infrastructure
- If this is a control plane machine, deregister the instance from the provider’s control plane load balancer (optional)
- If any errors are encountered, exit the reconciliation
- Remove the provider-specific finalizer from the resource
- Patch the resource to persist changes
RBAC
Provider controller
A machine infrastructure provider must have RBAC permissions for the types it defines. If you are using kubebuilder to
generate new API types, these permissions should be configured for you automatically. For example, the AWS provider has
the following configuration for its AWSMachine type:
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=awsmachines,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=awsmachines/status,verbs=get;update;patch
A machine infrastructure provider may also need RBAC permissions for other types, such as Cluster and Machine. If
you need read-only access, you can limit the permissions to get, list, and watch. You can use the following
configuration for retrieving Cluster and Machine resources:
// +kubebuilder:rbac:groups=cluster.x-k8s.io,resources=clusters;clusters/status,verbs=get;list;watch
// +kubebuilder:rbac:groups=cluster.x-k8s.io,resources=machines;machines/status,verbs=get;list;watch
Cluster API controllers
The Cluster API controller for Machine resources is configured with full read/write RBAC
permissions for all resources in the infrastructure.cluster.x-k8s.io API group. This group
represents all machine infrastructure providers for SIG Cluster Lifecycle-sponsored provider
subprojects. If you are writing a provider not sponsored by the SIG, you must grant full read/write
RBAC permissions for the “infrastructure machine” resource in your API group to the Cluster API
manager’s ServiceAccount. ClusterRoles can be granted using the aggregation label
cluster.x-k8s.io/aggregate-to-manager: "true". The following is an example ClusterRole for a
FooMachine resource:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: capi-foo-machines
labels:
cluster.x-k8s.io/aggregate-to-manager: "true"
rules:
- apiGroups:
- infrastructure.foo.com
resources:
- foomachines
verbs:
- create
- delete
- get
- list
- patch
- update
- watch
Note, the write permissions allow the Machine controller to set owner references and labels on the
“infrastructure machine” resources; they are not used for general mutations of these resources.
Bootstrap Provider Specification
Overview
A bootstrap provider generates bootstrap data that is used to bootstrap a Kubernetes node.
Data Types
Bootstrap API resource
A bootstrap provider must define an API type for bootstrap resources. The type:
- Must belong to an API group served by the Kubernetes apiserver
- May be implemented as a CustomResourceDefinition, or as part of an aggregated apiserver
- Must be namespace-scoped
- Must have the standard Kubernetes “type metadata” and “object metadata”
- Should have a
specfield containing fields relevant to the bootstrap provider - Must have a
statusfield with the following:- Required fields:
ready(boolean): indicates the bootstrap data has been generated and is readydataSecretName(string): the name of the secret that stores the generated bootstrap data
- Optional fields:
failureReason(string): indicates there is a fatal problem reconciling the bootstrap data; meant to be suitable for programmatic interpretationfailureMessage(string): indicates there is a fatal problem reconciling the bootstrap data; meant to be a more descriptive value thanfailureReason
- Required fields:
Note: because the dataSecretName is part of status, this value must be deterministically recreatable from the data in the
Cluster, Machine, and/or bootstrap resource. If the name is randomly generated, it is not always possible to move
the resource and its associated secret from one management cluster to another.
Bootstrap Secret
The Secret containing bootstrap data must:
- Use the API resource’s
status.dataSecretNamefor its name - Have the label
cluster.x-k8s.io/cluster-nameset to the name of the cluster - Have a controller owner reference to the API resource
- Have a single key,
value, containing the bootstrap data
Behavior
A bootstrap provider must respond to changes to its bootstrap resources. This process is typically called reconciliation. The provider must watch for new, updated, and deleted resources and respond accordingly.
The following diagram shows the typical logic for a bootstrap provider:
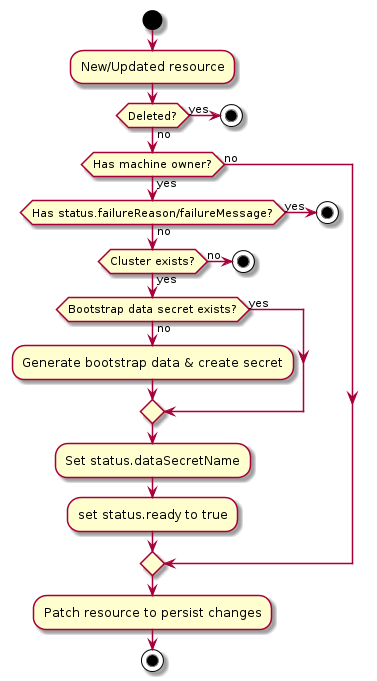
- If the resource does not have a
Machineowner, exit the reconciliation- The Cluster API
Machinereconciler populates this based on the value in theMachine‘sspec.bootstrap.configReffield.
- The Cluster API
- If the resource has
status.failureReasonorstatus.failureMessageset, exit the reconciliation - If the
Clusterto which this resource belongs cannot be found, exit the reconciliation - Deterministically generate the name for the bootstrap data secret
- Try to retrieve the
Secretwith the name from the previous step- If it does not exist, generate bootstrap data and create the
Secret
- If it does not exist, generate bootstrap data and create the
- Set
status.dataSecretNameto the generated name - Set
status.readyto true - Patch the resource to persist changes
Sentinel File
A bootstrap provider’s bootstrap data must create /run/cluster-api/bootstrap-success.complete (or C:\run\cluster-api\bootstrap-success.complete for Windows machines) upon successful bootstrapping of a Kubernetes node. This allows infrastructure providers to detect and act on bootstrap failures.
RBAC
Provider controller
A bootstrap provider must have RBAC permissions for the types it defines, as well as the bootstrap data Secret
resources it manages. If you are using kubebuilder to generate new API types, these permissions should be configured
for you automatically. For example, the Kubeadm bootstrap provider the following configuration for its KubeadmConfig
type:
// +kubebuilder:rbac:groups=bootstrap.cluster.x-k8s.io,resources=kubeadmconfigs;kubeadmconfigs/status,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups="",resources=secrets,verbs=get;list;watch;create;update;patch;delete
A bootstrap provider may also need RBAC permissions for other types, such as Cluster. If you need
read-only access, you can limit the permissions to get, list, and watch. The following
configuration can be used for retrieving Cluster resources:
// +kubebuilder:rbac:groups=cluster.x-k8s.io,resources=clusters;clusters/status,verbs=get;list;watch
Cluster API controllers
The Cluster API controller for Machine resources is configured with full read/write RBAC permissions for all resources
in the bootstrap.cluster.x-k8s.io API group. This group represents all bootstrap providers for SIG Cluster
Lifecycle-sponsored provider subprojects. If you are writing a provider not sponsored by the SIG, you must add new RBAC
permissions for the Cluster API manager-role role, granting it full read/write access to the bootstrap resource in
your API group.
Note, the write permissions allow the Machine controller to set owner references and labels on the bootstrap
resources; they are not used for general mutations of these resources.
Overview
In order to demonstrate how to develop a new Cluster API provider we will use
kubebuilder to create an example provider. For more information on kubebuilder
and CRDs in general we highly recommend reading the Kubebuilder Book.
Much of the information here was adapted directly from it.
This is an infrastructure provider - tasked with managing provider-specific resources for clusters and machines. There are also bootstrap providers, which turn machines into Kubernetes nodes.
Prerequisites
- Install
kubectl - Install
kustomize - Install
kubebuilder
tl;dr
# Install kubectl
brew install kubernetes-cli
# Install kustomize
brew install kustomize
# Install kubectl
KUBECTL_VERSION=$(curl -sf https://dl.k8s.io/release/stable.txt)
curl -fLO https://dl.k8s.io/release/${KUBECTL_VERSION}/bin/linux/amd64/kubectl
# Install kustomize
OS_TYPE=linux
curl -sf https://api.github.com/repos/kubernetes-sigs/kustomize/releases/latest |\
grep browser_download |\
grep ${OS_TYPE} |\
cut -d '"' -f 4 |\
xargs curl -f -O -L
mv kustomize_*_${OS_TYPE}_amd64 /usr/local/bin/kustomize
chmod u+x /usr/local/bin/kustomize
# Install Kubebuilder
os=$(go env GOOS)
arch=$(go env GOARCH)
# download kubebuilder and extract it to tmp
curl -sL https://go.kubebuilder.io/dl/2.1.0/${os}/${arch} | tar -xz -C /tmp/
# move to a long-term location and put it on your path
# (you'll need to set the KUBEBUILDER_ASSETS env var if you put it somewhere else)
sudo mv /tmp/kubebuilder_2.1.0_${os}_${arch} /usr/local/kubebuilder
export PATH=$PATH:/usr/local/kubebuilder/bin
Repository Naming
The naming convention for new Cluster API provider repositories
is generally of the form cluster-api-provider-${env}, where ${env} is a,
possibly short, name for the environment in question. For example
cluster-api-provider-gcp is an implementation for the Google Cloud Platform,
and cluster-api-provider-aws is one for Amazon Web Services. Note that an
environment may refer to a cloud, bare metal, virtual machines, or any other
infrastructure hosting Kubernetes. Finally, a single environment may include
more than one variant. So for example,
cluster-api-provider-aws may include both an implementation based on EC2 as
well as one based on their hosted EKS solution.
A note on Acronyms
Because these names end up being so long, developers of Cluster API frequently refer to providers by acronyms. Cluster API itself becomes CAPI, pronounced “Cappy.” cluster-api-provider-aws is CAPA, pronounced “KappA.” cluster-api-provider-gcp is CAPG, pronounced “Cap Gee,” and so on.
Resource Naming
For the purposes of this guide we will create a provider for a
service named mailgun. Therefore the name of the repository will be
cluster-api-provider-mailgun.
Every Kubernetes resource has a Group, Version and Kind that uniquely identifies it.
- The resource Group is similar to package in a language.
It disambiguates different APIs that may happen to have identically named Kinds.
Groups often contain a domain name, such as k8s.io.
The domain for Cluster API resources is
cluster.x-k8s.io, and infrastructure providers generally useinfrastructure.cluster.x-k8s.io. - The resource Version defines the stability of the API and its backward compatibility guarantees. Examples include v1alpha1, v1beta1, v1, etc. and are governed by the Kubernetes API Deprecation Policy 1. Your provider should expect to abide by the same policies.
- The resource Kind is the name of the objects we’ll be creating and modifying.
In this case it’s
MailgunMachineandMailgunCluster.
For example, our cluster object will be:
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3
kind: MailgunCluster
https://kubernetes.io/docs/reference/using-api/deprecation-policy/
Create a repository
mkdir cluster-api-provider-mailgun
cd src/sigs.k8s.io/cluster-api-provider-mailgun
git init
You’ll then need to set up go modules
$ go mod init github.com/liztio/cluster-api-provider-mailgun
go: creating new go.mod: module github.com/liztio/cluster-api-provider-mailgun
Generate scaffolding
kubebuilder init --domain cluster.x-k8s.io
kubebuilder init will create the basic repository layout, including a simple containerized manager.
It will also initialize the external go libraries that will be required to build your project.
Commit your changes so far:
git commit -m "Generate scaffolding."
Generate provider resources for Clusters and Machines
Here you will be asked if you want to generate resources and controllers. You’ll want both of them:
kubebuilder create api --group infrastructure --version v1alpha3 --kind MailgunCluster
kubebuilder create api --group infrastructure --version v1alpha3 --kind MailgunMachine
Create Resource under pkg/apis [y/n]?
y
Create Controller under pkg/controller [y/n]?
y
Add Status subresource
The status subresource lets Spec and Status requests for custom resources be addressed separately so requests don’t conflict with each other. It also lets you split RBAC rules between Spec and Status. It’s stable in Kubernetes as of v1.16, but you will have to manually enable it in Kubebuilder.
Add the subresource:status annotation to your <provider>cluster_types.go <provider>machine_types.go
// +kubebuilder:subresource:status
// +kubebuilder:object:root=true
// MailgunCluster is the Schema for the mailgunclusters API
type MailgunCluster struct {
// +kubebuilder:subresource:status
// +kubebuilder:object:root=true
// MailgunMachine is the Schema for the mailgunmachines API
type MailgunMachine struct {
And regenerate the CRDs:
make manifests
Apply further customizations
The cluster API CRDs should be further customized:
- Apply the contract version label to support conversions
- Upgrade to CRD v1
- Set “matchPolicy=Equivalent” kubebuilder marker for webhooks
- Refactor the kustomize config folder to support multi-tenancy
- Ensure you are compliant with the clusterctl provider contract
Commit your changes
git add .
git commit -m "Generate Cluster and Machine resources."
Defining your API
The API generated by Kubebuilder is just a shell. Your actual API will likely have more fields defined on it.
Kubernetes has a lot of conventions and requirements around API design. The Kubebuilder docs have some helpful hints on how to design your types.
Let’s take a look at what was generated for us:
// MailgunClusterSpec defines the desired state of MailgunCluster
type MailgunClusterSpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "make" to regenerate code after modifying this file
}
// MailgunClusterStatus defines the observed state of MailgunCluster
type MailgunClusterStatus struct {
// INSERT ADDITIONAL STATUS FIELD - define observed state of cluster
// Important: Run "make" to regenerate code after modifying this file
}
Our API is based on Mailgun, so we’re going to have some email based fields:
type Priority string
const (
// PriorityUrgent means do this right away
PriorityUrgent = Priority("Urgent")
// PriorityUrgent means do this immediately
PriorityExtremelyUrgent = Priority("ExtremelyUrgent")
// PriorityBusinessCritical means you absolutely need to do this now
PriorityBusinessCritical = Priority("BusinessCritical")
)
// MailgunClusterSpec defines the desired state of MailgunCluster
type MailgunClusterSpec struct {
// Priority is how quickly you need this cluster
Priority Priority `json:"priority"`
// Request is where you ask extra nicely
Request string `json:"request"`
// Requester is the email of the person sending the request
Requester string `json:"requester"`
}
// MailgunClusterStatus defines the observed state of MailgunCluster
type MailgunClusterStatus struct {
// MessageID is set to the message ID from Mailgun when our message has been sent
MessageID *string `json:"response"`
}
As the deleted comments request, run make manager manifests to regenerate some of the generated data files afterwards.
git add .
git commit -m "Added cluster types"
Controllers and Reconciliation
From the kubebuilder book:
Controllers are the core of Kubernetes, and of any operator.
It’s a controller’s job to ensure that, for any given object, the actual state of the world (both the cluster state, and potentially external state like running containers for Kubelet or loadbalancers for a cloud provider) matches the desired state in the object. Each controller focuses on one root Kind, but may interact with other Kinds.
We call this process reconciling.
Right now, we can create objects in our API but we won’t do anything about it. Let’s fix that.
Let’s see the Code
Kubebuilder has created our first controller in controllers/mailguncluster_controller.go. Let’s take a look at what got generated:
// MailgunClusterReconciler reconciles a MailgunCluster object
type MailgunClusterReconciler struct {
client.Client
Log logr.Logger
}
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=mailgunclusters,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=mailgunclusters/status,verbs=get;update;patch
func (r *MailgunClusterReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
_ = context.Background()
_ = r.Log.WithValues("mailguncluster", req.NamespacedName)
// your logic here
return ctrl.Result{}, nil
}
RBAC Roles
Those // +kubebuilder... lines tell kubebuilder to generate RBAC roles so the manager we’re writing can access its own managed resources.
We also need to add roles that will let it retrieve (but not modify) Cluster API objects.
So we’ll add another annotation for that:
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=mailgunclusters,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=mailgunclusters/status,verbs=get;update;patch
// +kubebuilder:rbac:groups=cluster.x-k8s.io,resources=clusters;clusters/status,verbs=get;list;watch
Make sure to add the annotation to both MailgunClusterReconciler and MailgunMachineReconciler.
Regenerate the RBAC roles after you are done:
make manifests
State
Let’s focus on that struct first.
First, a word of warning: no guarantees are made about parallel access, both on one machine or multiple machines.
That means you should not store any important state in memory: if you need it, write it into a Kubernetes object and store it.
We’re going to be sending mail, so let’s add a few extra fields:
// MailgunClusterReconciler reconciles a MailgunCluster object
type MailgunClusterReconciler struct {
client.Client
Log logr.Logger
Mailgun mailgun.Mailgun
Recipient string
}
Reconciliation
Now it’s time for our Reconcile function. Reconcile is only passed a name, not an object, so let’s retrieve ours.
Here’s a naive example:
func (r *MailgunClusterReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
ctx := context.Background()
_ = r.Log.WithValues("mailguncluster", req.NamespacedName)
var cluster infrastructurev1alpha3.MailgunCluster
if err := r.Get(ctx, req.NamespacedName, &cluster); err != nil {
return ctrl.Result{}, err
}
return ctrl.Result{}, nil
}
By returning an error, we request that our controller will get Reconcile() called again.
That may not always be what we want - what if the object’s been deleted? So let’s check that:
var cluster infrastructurev1alpha3.MailgunCluster
if err := r.Get(ctx, req.NamespacedName, &cluster); err != nil {
// import apierrors "k8s.io/apimachinery/pkg/api/errors"
if apierrors.IsNotFound(err) {
return ctrl.Result{}, nil
}
return ctrl.Result{}, err
}
Now, if this were any old kubebuilder project we’d be done, but in our case we have one more object to retrieve.
Cluster API splits a cluster into two objects: the Cluster defined by Cluster API itself.
We’ll want to retrieve that as well.
Luckily, cluster API provides a helper for us.
cluster, err := util.GetOwnerCluster(ctx, r.Client, &mg)
if err != nil {
return ctrl.Result{}, err
}
client-go versions
At the time this document was written, kubebuilder pulls client-go version 1.14.1 into go.mod (it looks like k8s.io/client-go v11.0.1-0.20190409021438-1a26190bd76a+incompatible).
If you encounter an error when compiling like:
../pkg/mod/k8s.io/client-go@v11.0.1-0.20190409021438-1a26190bd76a+incompatible/rest/request.go:598:31: not enough arguments in call to watch.NewStreamWatcher
have (*versioned.Decoder)
want (watch.Decoder, watch.Reporter)`
You may need to bump client-go. At time of writing, that means 1.15, which looks like: k8s.io/client-go v11.0.1-0.20190409021438-1a26190bd76a+incompatible.
The fun part
More Documentation: The Kubebuilder Book has some excellent documentation on many things, including how to write good controllers!
Now that we have our objects, it’s time to do something with them! This is where your provider really comes into its own. In our case, let’s try sending some mail:
subject := fmt.Sprintf("[%s] New Cluster %s requested", mgCluster.Spec.Priority, cluster.Name)
body := fmt.Sprint("Hello! One cluster please.\n\n%s\n", mgCluster.Spec.Request)
msg := mailgun.NewMessage(mgCluster.Spec.Requester, subject, body, r.Recipient)
_, _, err = r.Mailgun.Send(msg)
if err != nil {
return ctrl.Result{}, err
}
Idempotency
But wait, this isn’t quite right.
Reconcile() gets called periodically for updates, and any time any updates are made.
That would mean we’re potentially sending an email every few minutes!
This is an important thing about controllers: they need to be idempotent.
So in our case, we’ll store the result of sending a message, and then check to see if we’ve sent one before.
if mgCluster.Status.MessageID != nil {
// We already sent a message, so skip reconciliation
return ctrl.Result{}, nil
}
subject := fmt.Sprintf("[%s] New Cluster %s requested", mgCluster.Spec.Priority, cluster.Name)
body := fmt.Sprintf("Hello! One cluster please.\n\n%s\n", mgCluster.Spec.Request)
msg := mailgun.NewMessage(mgCluster.Spec.Requester, subject, body, r.Recipient)
_, msgID, err := r.Mailgun.Send(msg)
if err != nil {
return ctrl.Result{}, err
}
// patch from sigs.k8s.io/cluster-api/util/patch
helper, err := patch.NewHelper(&mgCluster, r.Client)
if err != nil {
return ctrl.Result{}, err
}
mgCluster.Status.MessageID = &msgID
if err := helper.Patch(ctx, &mgCluster); err != nil {
return ctrl.Result{}, errors.Wrapf(err, "couldn't patch cluster %q", mgCluster.Name)
}
return ctrl.Result{}, nil
A note about the status
Usually, the Status field should only be values that can be computed from existing state.
Things like whether a machine is running can be retrieved from an API, and cluster status can be queried by a healthcheck.
The message ID is ephemeral, so it should properly go in the Spec part of the object.
Anything that can’t be recreated, either with some sort of deterministic generation method or by querying/observing actual state, needs to be in Spec.
This is to support proper disaster recovery of resources.
If you have a backup of your cluster and you want to restore it, Kubernetes doesn’t let you restore both spec & status together.
We use the MessageID as a Status here to illustrate how one might issue status updates in a real application.
Update main.go with your new fields
If you added fields to your reconciler, you’ll need to update main.go.
Right now, it probably looks like this:
if err = (&controllers.MailgunClusterReconciler{
Client: mgr.GetClient(),
Log: ctrl.Log.WithName("controllers").WithName("MailgunCluster"),
}).SetupWithManager(mgr); err != nil {
setupLog.Error(err, "unable to create controller", "controller", "MailgunCluster")
os.Exit(1)
}
Let’s add our configuration. We’re going to use environment variables for this:
domain := os.Getenv("MAILGUN_DOMAIN")
if domain == "" {
setupLog.Info("missing required env MAILGUN_DOMAIN")
os.Exit(1)
}
apiKey := os.Getenv("MAILGUN_API_KEY")
if apiKey == "" {
setupLog.Info("missing required env MAILGUN_API_KEY")
os.Exit(1)
}
recipient := os.Getenv("MAIL_RECIPIENT")
if recipient == "" {
setupLog.Info("missing required env MAIL_RECIPIENT")
os.Exit(1)
}
mg := mailgun.NewMailgun(domain, apiKey)
if err = (&controllers.MailgunClusterReconciler{
Client: mgr.GetClient(),
Log: ctrl.Log.WithName("controllers").WithName("MailgunCluster"),
Mailgun: mg,
Recipient: recipient,
}).SetupWithManager(mgr); err != nil {
setupLog.Error(err, "unable to create controller", "controller", "MailgunCluster")
os.Exit(1)
}
If you have some other state, you’ll want to initialize it here!
Building, Running, Testing
Docker Image Name
The patch in config/manager/manager_image_patch.yaml will be applied to the manager pod.
Right now there is a placeholder IMAGE_URL, which you will need to change to your actual image.
Development Images
It’s likely that you will want one location and tag for release development, and another during development.
The approach most Cluster API projects is using a Makefile that uses sed to replace the image URL on demand during development.
Deployment
cert-manager
Cluster API uses cert-manager to manage the certificates it needs for its webhooks.
Before you apply Cluster API’s yaml, you should install cert-manager
kubectl apply -f https://github.com/jetstack/cert-manager/releases/download/<version>/cert-manager.yaml
Cluster API
Before you can deploy the infrastructure controller, you’ll need to deploy Cluster API itself.
You can use a precompiled manifest from the release page, or clone cluster-api and apply its manifests using kustomize.
cd cluster-api
kustomize build config/ | kubectl apply -f-
Check the status of the manager to make sure it’s running properly
$ kubectl describe -n capi-system pod | grep -A 5 Conditions
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Your provider
Now you can apply your provider as well:
$ cd cluster-api-provider-mailgun
$ kustomize build config/ | envsubst | kubectl apply -f-
$ kubectl describe -n cluster-api-provider-mailgun-system pod | grep -A 5 Conditions
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Tiltfile
Cluster API development requires a lot of iteration, and the “build, tag, push, update deployment” workflow can be very tedious. Tilt makes this process much simpler by watching for updates, then automatically building and deploying them.
You can visit some example repositories, but you can get started by writing out a yaml manifest and using the following Tiltfile
kustomize build config/ | envsubst > capm.yaml
allow_k8s_contexts('kubernetes-admin@kind)
k8s_yaml('capm.yaml')
docker_build('<your docker username or repository url>/cluster-api-controller-mailgun-amd64', '.')
You can then use Tilt to watch the logs coming off your container.
Your first Cluster
Let’s try our cluster out. We’ll make some simple YAML:
apiVersion: cluster.x-k8s.io/v1alpha2
kind: Cluster
metadata:
name: hello-mailgun
spec:
clusterNetwork:
pods:
cidrBlocks: ["192.168.0.0/16"]
infrastructureRef:
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3
kind: MailgunCluster
name: hello-mailgun
---
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3
kind: MailgunCluster
metadata:
name: hello-mailgun
spec:
priority: "ExtremelyUrgent"
request: "Please make me a cluster, with sugar on top?"
requester: "cluster-admin@example.com"
We apply it as normal with kubectl apply -f <filename>.yaml.
If all goes well, you should be getting an email to the address you configured when you set up your management cluster:
Conclusion
Obviously, this is only the first step. We need to implement our Machine object too, and log events, handle updates, and many more things.
Hopefully you feel empowered to go out and create your own provider now. The world is your Kubernetes-based oyster!
CustomResourceDefinitions relationships
There are many resources that appear in the Cluster API. In this section, we use diagrams to illustrate the most common relationships between Cluster API resources.
Control plane machines relationships
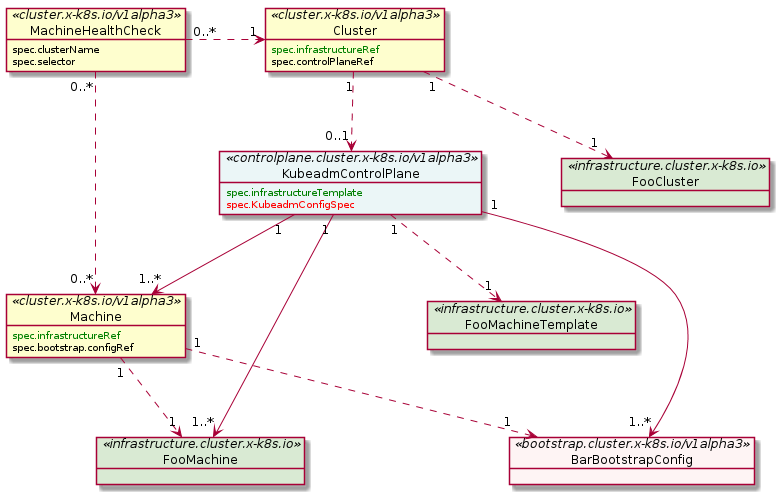
Worker machines relationships
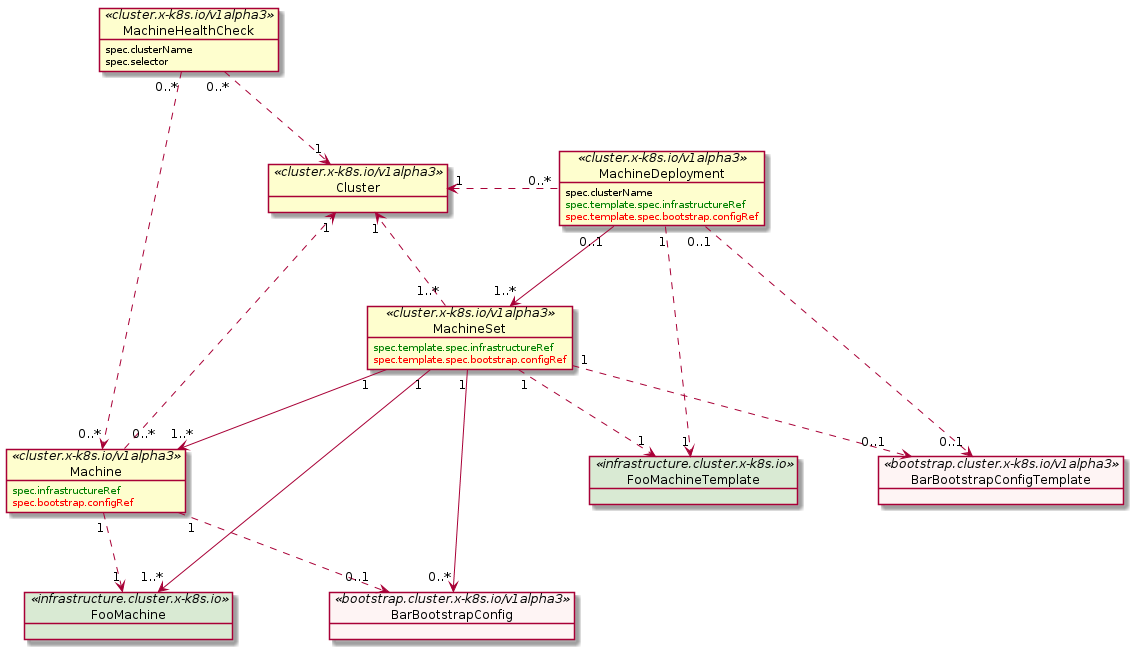
Troubleshooting
Node bootstrap failures when using CABPK with cloud-init
Failures during Node bootstrapping can have a lot of different causes. For example, Cluster API resources might be misconfigured or there might be problems with the network. The following steps describe how bootstrap failures can be troubleshooted systematically.
- Access the Node via ssh.
- Take a look at cloud-init logs via
less /var/log/cloud-init-output.logorjournalctl -u cloud-init --since "1 day ago". (Note: cloud-init persists logs of the commands it executes (like kubeadm) only after they have returned.) - It might also be helpful to take a look at
journalctl --since "1 day ago". - If you see that kubeadm times out waiting for the static Pods to come up, take a look at:
- containerd:
crictl ps -a,crictl logs,journalctl -u containerd - Kubelet:
journalctl -u kubelet --since "1 day ago"(Note: it might be helpful to increase the Kubelet log level by e.g. setting--v=8viasystemctl edit --full kubelet && systemctl restart kubelet)
- containerd:
- If Node bootstrapping consistently fails and the kubeadm logs are not verbose enough, the
kubeadmverbosity can be increased viaKubeadmConfigSpec.Verbosity.
Labeling nodes with reserved labels such as node-role.kubernetes.io fails with kubeadm error during bootstrap
Self-assigning Node labels such as node-role.kubernetes.io using the kubelet --node-labels flag
(see kubeletExtraArgs in the CABPK examples)
is not possible due to a security measure imposed by the
NodeRestriction admission controller
that kubeadm enables by default.
Assigning such labels to Nodes must be done after the bootstrap process has completed:
kubectl label nodes <name> node-role.kubernetes.io/worker=""
For convenience, here is an example one-liner to do this post installation
kubectl get nodes --no-headers -l '!node-role.kubernetes.io/master' -o jsonpath='{range .items[*]}{.metadata.name}{"\n"}' | xargs -I{} kubectl label node {} node-role.kubernetes.io/worker=''
Cluster API with Docker
When provisioning workload clusters using Cluster API with Docker infrastructure, provisioning might be stuck:
-
if there are stopped containers on your machine from previous runs. Clean unused containers with docker rm -f .
-
if the docker space on your disk is being exhausted
- Run docker system df to inspect the disk space consumed by Docker resources.
- Run docker system prune --volumes to prune dangling images, containers, volumes and networks.
Failed clusterctl init - ‘failed to get cert-manager object’
When using older versions of Cluster API 0.4 and 1.0 releases - 0.4.6, 1.0.3 and older respectively - Cert Manager may not be downloadable due to a change in the repository location. This will cause clusterctl init to fail with the error:
$ cluster-api % clusterctl init --infrastructure docker
Fetching providers
Installing cert-manager Version="v1.5.3"
Error: action failed after 10 attempts: failed to get cert-manager object /, Kind=, /: Object 'Kind' is missing in 'unstructured object has no kind'
This error was fixed in more recent Cluster API releases on the 0.4 and 1.0 release branches. The simplest way to resolve the issue is to upgrade to a newer version of Cluster API for a given release. For who need to continue using an older release it is possible to override the repository used by clusterctl init in the clusterctl config file. The default location of this file is in ~/.cluster-api/clusterctl.yaml.
To do so add the following to the file:
cert-manager:
url: "https://github.com/cert-manager/cert-manager/releases/latest/cert-manager.yaml"
Alternatively a Cert Manager yaml file can be placed in the clusterctl overrides layer which is by default in $HOME/.cluster-api/overrides. A Cert Manager yaml file can be placed at $(HOME)/.cluster-api/overrides/cert-manager/v1.5.3/cert-manager.yaml
More information on the clusterctl config file can be found at its page in the book
98e3f975d (Fix cert manager repo and add troubleshooting guide)
Reference
This section contains various resources that define the Cluster API project.
Table of Contents
A | B | C | D | H | I | K | M | N | O | P | S | T | W
A
Add-ons
Services beyond the fundamental components of Kubernetes.
- Core Add-ons: Addons that are required to deploy a Kubernetes-conformant cluster: DNS, kube-proxy, CNI.
- Additional Add-ons: Addons that are not required for a Kubernetes-conformant cluster (e.g. metrics/Heapster, Dashboard).
B
Bootstrap
The process of turning a server into a Kubernetes node. This may involve assembling data to provide when creating the server that backs the Machine, as well as runtime configuration of the software running on that server.
Bootstrap cluster
A temporary cluster that is used to provision a Target Management cluster.
C
CAEP
Cluster API Enhancement Proposal - patterned after KEP. See template
CAPI
Core Cluster API
CAPA
Cluster API Provider AWS
CABPK
Cluster API Bootstrap Provider Kubeadm
CAPD
Cluster API Provider Docker
CAPDO
Cluster API Provider DigitalOcean
CAPG
Cluster API Google Cloud Provider
CAPIBM
Cluster API Provider IBM Cloud
CAPN
Cluster API Provider Nested
CAPO
Cluster API Provider OpenStack
CAPV
Cluster API Provider vSphere
CAPZ
Cluster API Provider Azure
Cluster
A full Kubernetes deployment. See Management Cluster and Workload Cluster.
Cluster API
Or Cluster API project
The Cluster API sub-project of the SIG-cluster-lifecycle. It is also used to refer to the software components, APIs, and community that produce them.
Control plane
The set of Kubernetes services that form the basis of a cluster. See also https://kubernetes.io/docs/concepts/#kubernetes-control-plane There are two variants:
- Self-provisioned: A Kubernetes control plane consisting of pods or machines wholly managed by a single Cluster API deployment.
- External: A control plane offered and controlled by some system other than Cluster API (e.g., GKE, AKS, EKS, IKS).
D
Default implementation
A feature implementation offered as part of the Cluster API project, infrastructure providers can swap it out for a different one.
H
Horizontal Scaling
The ability to add more machines based on policy and well defined metrics. For example, add a machine to a cluster when CPU load average > (X) for a period of time (Y).
Host
see Server
I
Infrastructure provider
A source of computational resources (e.g. machines, networking, etc.). Examples for cloud include AWS, Azure, Google, etc.; for bare metal include VMware, MAAS, metal3.io, etc. When there is more than one way to obtain resources from the same infrastructure provider (e.g. EC2 vs. EKS) each way is referred to as a variant.
Instance
see Server
Immutability
A resource that does not mutate. In kubernetes we often state the instance of a running pod is immutable or does not change once it is run. In order to make a change, a new pod is run. In the context of Cluster API we often refer to a running instance of a Machine as being immutable, from a Cluster API perspective.
K
Kubernetes-conformant
Or Kubernetes-compliant
A cluster that passes the Kubernetes conformance tests.
k/k
Refers to the main Kubernetes git repository or the main Kubernetes project.
M
Machine
Or Machine Resource
The Custom Resource for Kubernetes that represents a request to have a place to run kubelet.
See also: Server
Manage a cluster
Perform create, scale, upgrade, or destroy operations on the cluster.
Management cluster
The cluster where one or more Infrastructure Providers run, and where resources (e.g. Machines) are stored. Typically referred to when you are provisioning multiple workload clusters.
Multi-tenancy
Multi tenancy in Cluster API defines the capability of an infrastructure provider to manage different credentials, each one of them corresponding to an infrastructure tenant.
Please note that up until v1alpha3 this concept had a different meaning, referring to the capability to run multiple instances of the same provider, each one with its own credentials; starting from v1alpha4 we are disambiguating the two concepts.
See Multi-tenancy and Support multiple instances.
N
Node pools
A node pool is a group of nodes within a cluster that all have the same configuration.
O
Operating system
Or OS
A generically understood combination of a kernel and system-level userspace interface, such as Linux or Windows, as opposed to a particular distribution.
P
Pivot
Pivot is a process for moving the provider components and declared cluster-api resources from a Source Management cluster to a Target Management cluster.
The pivot process is also used for deleting a management cluster and could also be used during an upgrade of the management cluster.
Provider
Provider components
Refers to the YAML artifact a provider publishes as part of their releases which is required to use the provider components, it usually contains Custom Resource Definitions (CRDs), Deployments (to run the controller manager), RBAC, etc.
Provider implementation
Existing Cluster API implementations consist of generic and infrastructure provider-specific logic. The infrastructure provider-specific logic is currently maintained in infrastructure provider repositories.
S
Scaling
Unless otherwise specified, this refers to horizontal scaling.
Stacked control plane
A control plane node where etcd is colocated with the Kubernetes API server, and is running as a static pod.
Server
The infrastructure that backs a Machine Resource, typically either a cloud instance, virtual machine, or physical host.
W
Workload Cluster
A cluster created by a ClusterAPI controller, which is not a bootstrap cluster, and is meant to be used by end-users, as opposed to by CAPI tooling.
Provider Implementations
The code in this repository is independent of any specific deployment environment. Provider specific code is being developed in separate repositories, some of which are also sponsored by SIG Cluster Lifecycle. Check provider’s documentation for updated info about which API version they are supporting.
Bootstrap
Infrastructure
- Alibaba Cloud
- AWS
- Azure
- Azure Stack HCI
- Baidu Cloud
- Metal3
- DigitalOcean
- Exoscale
- GCP
- IBM Cloud
- MAAS
- Nested
- OpenStack
- Packet
- Sidero
- Tencent Cloud
- vSphere
API Adopters
Following are the implementations managed by third-parties adopting the standard cluster-api and/or machine-api being developed here.
Ports used by Cluster API
| Name | Port Number | Description |
|---|---|---|
metrics | Port that exposes the metrics. This can be customized by setting the --metrics-bind-addr flag when starting the manager. The default is to only listen on localhost:8080 | |
webhook | 9443 | Webhook server port. To disable this set --webhook-port flag to 0. |
health | 9440 | Port that exposes the health endpoint. CThis can be customized by setting the --health-addr flag when starting the manager. |
profiler | Expose the pprof profiler. By default is not configured. Can set the --profiler-address flag. e.g. --profiler-address 6060 |
Note: external providers (e.g. infrastructure, bootstrap, or control-plane) might allocate ports differently, please refer to the respective documentation.
Kubernetes Community Code of Conduct
Please refer to our Kubernetes Community Code of Conduct
Contributing Guidelines
Read the following guide if you’re interested in contributing to cluster-api.
Contributor License Agreements
We’d love to accept your patches! Before we can take them, we have to jump a couple of legal hurdles.
Please fill out either the individual or corporate Contributor License Agreement (CLA). More information about the CLA and instructions for signing it can be found here.
NOTE: Only original source code from you and other people that have signed the CLA can be accepted into the *repository.
Finding Things That Need Help
If you’re new to the project and want to help, but don’t know where to start, we have a semi-curated list of issues that should not need deep knowledge of the system. Have a look and see if anything sounds interesting. Before starting to work on the issue, make sure that it doesn’t have a lifecycle/active label. If the issue has been assigned, reach out to the assignee. Alternatively, read some of the docs on other controllers and try to write your own, file and fix any/all issues that come up, including gaps in documentation!
Contributing a Patch
- If you haven’t already done so, sign a Contributor License Agreement (see details above).
- If working on an issue, signal other contributors that you are actively working on it using
/lifecycle active. - Fork the desired repo, develop and test your code changes.
- Submit a pull request.
- All code PR must be labeled with one of
- ⚠️ (:warning:, major or breaking changes)
- ✨ (:sparkles:, feature additions)
- 🐛 (:bug:, patch and bugfixes)
- 📖 (:book:, documentation or proposals)
- 🌱 (:seedling:, minor or other)
- All code PR must be labeled with one of
All changes must be code reviewed. Coding conventions and standards are explained in the official developer docs. Expect reviewers to request that you avoid common go style mistakes in your PRs.
Documentation changes
The documentation is published in form of a book at:
The source for the book is this folder containing markdown files and we use mdBook to build it into a static website.
After making changes locally you can run make serve-book which will build the HTML version
and start a web server so you can preview if the changes render correctly at
http://localhost:3000; the preview auto-updates when changes are detected.
Note: you don’t need to have mdBook installed, make serve-book will ensure
appropriate binaries for mdBook and any used plugins are downloaded into
hack/tools/bin/ directory.
When submitting the PR remember to label it with the 📖 (:book:) icon.
Releases
Cluster API uses GitHub milestones to track releases.
- Minor versions CAN be planned and scheduled twice in a calendar year.
- Each minor version is preceded with one or more planning session.
- Planning consists of one or more backlog grooming meetings, roadmap amendments, and CAEP proposal reviews.
- Patch versions CAN be planned and scheduled each month for each of the currently supported series (usually N and N-1).
- Code freeze is in effect 72 hours (3 days) before a release.
- Maintainers should communicate the code freeze date at a community meeting preceding the code freeze date.
- Only critical bug fixes may be merged in between freeze & release.
- Each bug MUST be associated with an open issue and properly triaged.
- PRs MUST be approved by at least 2 project maintainers.
- First approver should
/approveand/hold. - Second approver should
/approveand/hold cancel.
- First approver should
- E2E Test grid SHOULD be green before cutting a release.
- Dates in a release are approximations and always subject to change.
Nextmilestone is for work that has been triaged, but not prioritized/accepted for any release.
Proposal process (CAEP)
The Cluster API Enhacement Proposal is the process this project uses to adopt new features, changes to the APIs, changes to contracts between components, or changes to CLI interfaces.
The template, and accepted proposals live under docs/proposals.
- Proposals or requests for enhacements (RFEs) MUST be associated with an issue.
- Issues can be placed on the roadmap during planning if there is one or more folks that can dedicate time to writing a CAEP and/or implementating it after approval.
- A proposal SHOULD be introduced and discussed during the weekly community meetings,
Kubernetes SIG Cluster Lifecycle mailing list,
or discuss forum.
- Submit and discuss proposals using a collaborative writing platform, preferably Google Docs, share documents with edit permissions with the Kubernetes SIG Cluster Lifecycle mailing list.
- A proposal in a Google Doc MUST turn into a Pull Request.
- Proposals MUST be merged and in
implementablestate to be considered part of a major or minor release.
Triaging E2E test failures
When you submit a change to the Cluster API repository as set of validation jobs is automatically executed by prow and the results report is added to a comment at the end of your PR.
Some jobs run linters or unit test, and in case of failures, you can repeat the same operation locally using make test lint [etc..]
in order to investigate and potential issues. Prow logs usually provide hints about the make target you should use
(there might be more than one command that needs to be run).
End-to-end (E2E) jobs create real Kubernetes clusters by building Cluster API artifacts with the latest changes. In case of E2E test failures, usually it’s required to access the “Artifacts” link on the top of the prow logs page to triage the problem.
The artifact folder contains:
- A folder with the clusterctl local repository used for the test, where you can find components yaml and cluster templates.
- A folder with logs for all the clusters created during the test. Following logs/info are available:
- Controller logs (only if the cluster is a management cluster).
- Dump of the Cluster API resources (only if the cluster is a management cluster).
- Machine logs (only if the cluster is a workload cluster)
In case you want to run E2E test locally, please refer to the Testing guide. An overview over our e2e test jobs (and also all our other jobs) can be found in Jobs.
Reviewing a Patch
Reviews
Parts of the following content have been adapted from https://google.github.io/eng-practices/review.
Any Kubernetes organization member can leave reviews and /lgtm a pull request.
Code reviews should generally look at:
- Design: Is the code well-designed and consistent with the rest of the system?
- Functionality: Does the code behave as the author (or linked issue) intended? Is the way the code behaves good for its users?
- Complexity: Could the code be made simpler? Would another developer be able to easily understand and use this code when they come across it in the future?
- Tests: Does the code have correct and well-designed tests?
- Naming: Did the developer choose clear names for variable, types, methods, functions, etc.?
- Comments: Are the comments clear and useful? Do they explain the why rather than what?
- Documentation: Did the developer also update relevant documentation?
See Code Review in Cluster API for a more focused list of review items.
Approvals
Please see the Kubernetes community document on pull requests for more information about the merge process.
- A PR is approved by one of the project maintainers and owners after reviews.
- Approvals should be the very last action a maintainer takes on a pull request.
Backporting a Patch
Cluster API maintains older versions through release-X.Y branches.
We accept backports of bug fixes and non breaking features to the most recent release branch.
Backports MUST not be breaking for both API and behavioral changes.
We generally do not accept PRs against older release branches.
As an example:
Let’s assume that the most recent release branch is release-0.3
and the main branch is under active development for the next release.
A pull request that has been merged in the main branch can be backported to the release-0.3
if at least one maintainer approves the cherry pick, or asks the PR’s author to backport.
Features and bugs
Open issues to report bugs, or minor features.
For big feature, API and contract amendments, we follow the CAEP process as outlined below.
Experiments
Proof of concepts, code experiments, or other initiatives can live under the exp folder and behind a feature gate.
- Experiments SHOULD not modify any of the publicly exposed APIs (e.g. CRDs).
- Experiments SHOULD not modify any existing CRD types outside of the experimental API group(s).
- Experiments SHOULD not modify any existing command line contracts.
- Experiments MUST not cause any breaking changes to existing (non-experimental) Go APIs.
- Experiments SHOULD introduce utility helpers in the go APIs for experiments that cross multiple components and require support from bootstrap, control plane, or infrastructure providers.
- Experiments follow a strict lifecycle: Alpha -> Beta prior to Graduation.
- Alpha-stage experiments:
- SHOULD not be enabled by default and any feature gates MUST be marked as ‘Alpha’
- MUST be associated with a CAEP that is merged and in at least a provisional state
- MAY be considered inactive and marked as deprecated if the following does not happen within the course of 1 minor release cycle:
- Transition to Beta-stage
- Active development towards progressing to Beta-stage
- Either direct or downstream user evaluation
- Any deprecated Alpha-stage experiment MAY be removed in the next minor release.
- Beta-stage experiments:
- SHOULD be enabled by default, and any feature gates MUST be marked as ‘Beta’
- MUST be associated with a CAEP that is at least in the experimental state
- MUST support conversions for any type changes
- MUST remain backwards compatible unless updates are coinciding with a breaking Cluster API release
- MAY be considered inactive and marked as deprecated if the following does not happen within the course of 1 minor release cycle:
- Graduate
- Active development towards Graduation
- Either direct or downstream user consumption
- Any deprecated Beta-stage experiment MAY be removed after being deprecated for an entire minor release.
- Alpha-stage experiments:
- Experiment Graduation MUST coincide with a breaking Cluster API release
- Experiment Graduation checklist:
- MAY provide a way to be disabled, any feature gates MUST be marked as ‘GA’
- MUST undergo a full Kubernetes-style API review and update the CAEP with the plan to address any issues raised
- CAEP MUST be in an implementable state and is fully up to date with the current implementation
- CAEP MUST define transition plan for moving out of the experimental api group and code directories
- CAEP MUST define any upgrade steps required for Existing Management and Workload Clusters
- CAEP MUST define any upgrade steps required to be implemented by out-of-tree bootstrap, control plane, and infrastructure providers.
Breaking Changes
Breaking changes are generally allowed in the master branch, as this is the branch used to develop the next minor
release of Cluster API.
There may be times, however, when master is closed for breaking changes. This is likely to happen as we near the
release of a new minor version.
Breaking changes are not allowed in release branches, as these represent minor versions that have already been released. These versions have consumers who expect the APIs, behaviors, etc. to remain stable during the life time of the patch stream for the minor release.
Examples of breaking changes include:
- Removing or renaming a field in a CRD
- Removing or renaming a CRD
- Removing or renaming an exported constant, variable, type, or function
- Updating the version of critical libraries such as controller-runtime, client-go, apimachinery, etc.
- Some version updates may be acceptable, for picking up bug fixes, but maintainers must exercise caution when reviewing.
There may, at times, need to be exceptions where breaking changes are allowed in release branches. These are at the
discretion of the project’s maintainers, and must be carefully considered before merging. An example of an allowed
breaking change might be a fix for a behavioral bug that was released in an initial minor version (such as v0.3.0).
Google Doc Viewing Permissions
To gain viewing permissions to google docs in this project, please join either the kubernetes-dev or kubernetes-sig-cluster-lifecycle google group.
Issue and Pull Request Management
Anyone may comment on issues and submit reviews for pull requests. However, in order to be assigned an issue or pull request, you must be a member of the Kubernetes SIGs GitHub organization.
If you are a Kubernetes GitHub organization member, you are eligible for membership in the Kubernetes SIGs GitHub organization and can request membership by opening an issue against the kubernetes/org repo.
However, if you are a member of any of the related Kubernetes GitHub organizations but not of the Kubernetes org, you will need explicit sponsorship for your membership request. You can read more about Kubernetes membership and sponsorship here.
Cluster API maintainers can assign you an issue or pull request by leaving a /assign <your Github ID> comment on the
issue or pull request.
Jobs
This document intents to provide an overview over our jobs running via Prow, GitHub actions and Google Cloud Build.
Builds and Tests running on the default branch (currently v1alpha4)
NOTE: To see which test jobs execute which tests or e2e tests, you can click on the links which lead to the respective test overviews in testgrid.
Presubmits
Legend:
- ✳️️ jobs that don’t have to be run successfully for merge
- ✴️ jobs that are not triggered automatically for every commit
Prow Presubmits:
- pull-cluster-api-build-main
./scripts/ci-build.sh - ✳️️ ✴️ pull-cluster-api-make-main
./scripts/ci-make.sh - ✳️️ pull-cluster-api-apidiff-main
./scripts/ci-apidiff.sh - pull-cluster-api-verify
./scripts/ci-verify.sh - pull-cluster-api-test-main
./scripts/ci-test.sh - pull-cluster-api-test-main-mink8s
./scripts/ci-test.sh - pull-cluster-api-e2e-main
./scripts/ci-e2e.sh- GINKGO_FOCUS:
[PR-Blocking]
- GINKGO_FOCUS:
- ✳️️ pull-cluster-api-e2e-ipv6-main
./scripts/ci-e2e.sh- GINKGO_FOCUS:
[PR-Blocking], IP_FAMILY:IPv6
- GINKGO_FOCUS:
- ✳️️ ✴️ pull-cluster-api-e2e-full-main
./scripts/ci-e2e.sh- GINKGO_SKIP:
[PR-Blocking] [Conformance] [K8s-Upgrade](i.e. “no tags”)
- GINKGO_SKIP:
- ✳️️ ✴️ pull-cluster-api-e2e-workload-upgrade-1-22-latest-main
./scripts/ci-e2e.shFROM:stable-1.22TO:ci/latest-1.23- GINKGO_FOCUS:
[K8s-Upgrade]
- GINKGO_FOCUS:
GitHub Presubmit Workflows:
- golangci-lint: golangci/golangci-lint-action@v2 (locally via
make lint) - verify: kubernetes-sigs/kubebuilder-release-tools@v0.1 verifier
Postsubmits
Prow Postsubmits:
- post-cluster-api-push-images Google Cloud Build:
make release-staging,make -C test/infrastructure/docker release-staging
Periodics
Prow Periodics:
- periodic-cluster-api-verify-book-links-main
make verify-book-links - periodic-cluster-api-test-main
./scripts/ci-test.sh - periodic-cluster-api-e2e-main
./scripts/ci-e2e.sh- GINKGO_SKIP:
[Conformance] [K8s-Upgrade]
- GINKGO_SKIP:
- periodic-cluster-api-e2e-main-mink8s
./scripts/ci-e2e.sh- GINKGO_SKIP:
[Conformance] [K8s-Upgrade]
- GINKGO_SKIP:
- periodic-cluster-api-e2e-workload-upgrade-1-18-1-19-main
./scripts/ci-e2e.shFROM:stable-1.18TO:stable-1.19- GINKGO_FOCUS:
[K8s-Upgrade]
- GINKGO_FOCUS:
- periodic-cluster-api-e2e-workload-upgrade-1-19-1-20-main
./scripts/ci-e2e.shFROM:stable-1.19TO:stable-1.20- GINKGO_FOCUS:
[K8s-Upgrade]
- GINKGO_FOCUS:
- periodic-cluster-api-e2e-workload-upgrade-1-20-1-21-main
./scripts/ci-e2e.shFROM:stable-1.20TO:stable-1.21- GINKGO_FOCUS:
[K8s-Upgrade]
- GINKGO_FOCUS:
- periodic-cluster-api-e2e-workload-upgrade-1-21-1-22-main
./scripts/ci-e2e.shFROM:stable-1.21TO:stable-1.22- GINKGO_FOCUS:
[K8s-Upgrade]
- GINKGO_FOCUS:
- periodic-cluster-api-e2e-workload-upgrade-1-22-latest-main
./scripts/ci-e2e.shFROM:stable-1.22TO:ci/latest-1.23- GINKGO_FOCUS:
[K8s-Upgrade]
- GINKGO_FOCUS:
- cluster-api-push-images-nightly Google Cloud Build:
make release-staging-nightly,make -C test/infrastructure/docker release-staging-nightly
Builds and Tests running on releases
GitHub (On Release) Workflows:
- Update Homebrew Formula On Release: dawidd6/action-homebrew-bump-formula@v3 clusterctl
Code Review in Cluster API
Goal of this document
- To help newcomers to the project in implementing better PRs given the knowledge of what will be evaluated during the review.
- To help contributors in stepping up as a reviewer given a common understanding of what are the most relevant things to be evaluated during the review.
IMPORTANT: improving and maintaining this document is a collaborative effort, so we are encouraging constructive feedback and suggestions.
Resources
- Writing inclusive documentation
- Contributor Summit NA 2019: Keeping the Bar High - How to be a bad ass Code Reviewer
- Code Review Developer Guide - Google
- The Gentle Art Of Patch Review
Definition
(from Code Review Developer Guide - Google)
“A code review is a process where someone other than the author(s) of a piece of code examines that code”
Within the context of cluster API the following design items should be carefully evaluated when reviewing a PR:
Controller reentrancy
In CAPI most of the coding activities happen in controllers, and in order to make robust controllers, we should strive for implementing reentrant code.
A reentrant code can be interrupted in the middle of its execution and then safely be called again (”re-entered”); this concept, applied to Kubernetes controllers, means that a controller should be capable of recovering from interruptions, observe the current state of things, and act accordingly. e.g.
- We should not rely on flags/conditions from previous reconciliations since we are the controller setting the conditions. Instead, we should detect the status of things through introspection at every reconciliation and act accordingly.
- It is acceptable to rely on status flags/conditions that we’ve previously set as part of the current reconciliation.
- It is acceptable to rely on status flags/conditions set by other controllers.
NOTE: An important use case for reentrancy is the move operation, where Cluster API objects gets moved to a different management cluster and the controller running on the target cluster has to rebuild the object status from scratch by observing the current state of the underlying infrastructure.
API design
The API defines the main contract with the Cluster API users. As most of the APIs in Kubernetes, each API version encompasses a set of guarantees to the user in terms of support window, stability, and upgradability.
This makes API design a critical part of Cluster API development and usually:
- Breaking/major API changes should go through the CAEP process and be strictly synchronized with the major release cadence.
- Non-breaking/minor API changes can go in minor releases; non-breaking changes are generally:
- additive in nature
- default to pre-existing behavior
- optional as part of the API contract
On top of that, following API design considerations apply.
Serialization
The Kubernetes API-machinery that is used for API serialization is build on top of three technologies, most specifically:
- JSON serialization
- Open-API (for CRDs)
- the go type system
One of the areas where the interaction between those technologies is critical in the handling of optional values in the API; also the usage of nested slices might lead to problems in case of concurrent edits of the object.
Owner References
Cluster API leverages the owner ref chain of objects for several tasks, so it is crucial to evaluate the impacts of any change that can impact this area. Above all:
- The delete operation leverages on the owner ref chain for ensuring the cleanup of all the resources when a cluster is deleted;
- clusterctl move uses the owner ref chain for determining which object to move and the create/delete order.
The Cluster API contract
The Cluster API rules define a set of rules/conventions the different provider authors should follow in order to implement providers that can interact with the core Cluster API controllers, as documented here and here.
By extension, the Cluster API contract includes all the util methods that Cluster API exposes for
making the development of providers simpler and consistent (e.g. everything under /util or in /test/framework);
documentation of the utility is available here.
The Cluster API contract is linked to the version of the API (e.g. v1alpha3 Contract), and it is expected to provide the same set of guarantees in terms of support window, stability, and upgradability.
This makes any change that can impact the Cluster API contract critical and usually:
- Breaking/major contract changes should go through the CAEP process and be strictly synchronized with the major release cadence.
- Non-breaking/minor changes can go in minor releases; non-breaking changes are generally:
- Additive in nature
- Default to pre-existing behavior
- Optional as part of the API contract
Logging
- For CAPI controllers see Kubernetes logging conventions.
- For clusterctl see clusterctl logging conventions.
Testing
Testing plays an crucial role in ensuring the long term maintainability of the project.
In Cluster API we are committed to have a good test coverage and also to have a nice and consistent style in implementing tests. For more information see testing Cluster API.
Cluster API Version Support and Kubernetes Version Skew Policy
Supported Versions
The Cluster API team maintains release branches for (v1alpha4) v0.4 and (v1alpha3) v0.3, the two most recent releases.
Releases include these components:
- Core Provider
- Kubeadm Bootstrap Provider
- Kubeadm Control Plane Provider
- clusterctl client
All Infrastructure Providers are maintained by independent teams. Other Bootstrap and Control Plane Providers are also maintained by independent teams. For more information about their version support, see below.
Supported Kubernetes Versions
The project aims to keep the current minor release compatible with the actively supported Kubernetes minor releases, i.e., the current release (N), N-1, and N-2. To find out the exact range of Kubernetes versions supported by each component, please see the tables below.
See the following section to understand how cluster topology affects version support.
Kubernetes Version Support As A Function Of Cluster Topology
The Core Provider, Kubeadm Bootstrap Provider, and Kubeadm Control Plane Provider run on the Management Cluster, and clusterctl talks to that cluster’s API server.
In some cases, the Management Cluster is separate from the Workload Clusters. The Kubernetes version of the Management and Workload Clusters are allowed to be different.
Management Clusters and Workload Clusters can be upgraded independently and in any order, however, if you are additionally moving from v1alpha3 (v0.3.x) to v1alpha4 (v0.4.x) as part of the upgrade roll out, the management cluster will need to be upgraded to at least v1.19.x, prior to upgrading any workload cluster using Cluster API v1alpha4 (v0.4.x)
These diagrams show the relationships between components in a Cluster API release (yellow), and other components (white).
Management And Workload Cluster Are the Same (Self-hosted)
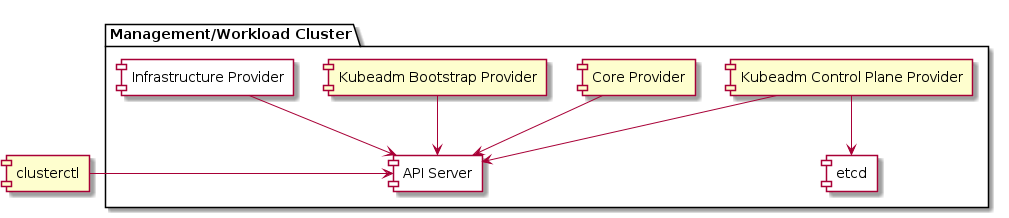
Management And Workload Clusters Are Separate
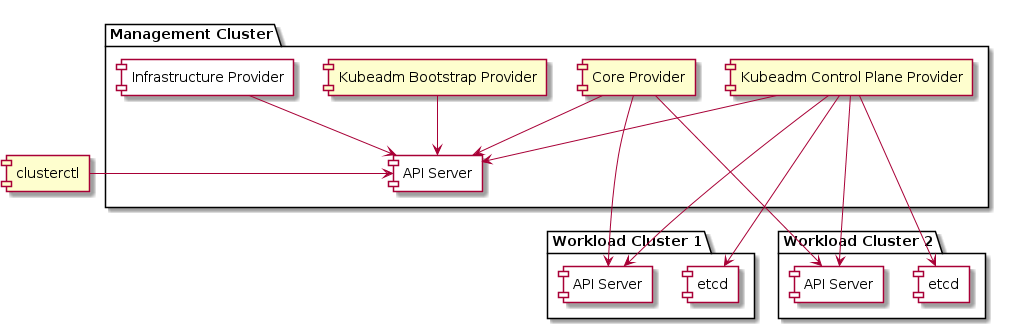
Release Components
Core Provider (cluster-api-controller)
| CAPI v1alpha3 (v0.3) Management | CAPI v1alpha3 (v0.3) Workload | CAPI v1alpha4 (v0.4) Management | CAPI v1alpha4 (v0.4) Workload | |
|---|---|---|---|---|
| Kubernetes v1.16 | ✓ | ✓ | ||
| Kubernetes v1.17 | ✓ | ✓ | ||
| Kubernetes v1.18 | ✓ | ✓ | ✓ | |
| Kubernetes v1.19 | ✓ | ✓ | ✓ | ✓ |
| Kubernetes v1.20 | ✓ | ✓ | ✓ | ✓ |
| Kubernetes v1.21 | ✓ | ✓ | ✓ | ✓ |
| Kubernetes v1.22 | ✓ | ✓ | ✓ |
The Core Provider also talks to API server of every Workload Cluster. Therefore, the Workload Cluster’s Kubernetes version must also be compatible.
Kubeadm Bootstrap Provider (kubeadm-bootstrap-controller)
| CAPI v1alpha3 (v0.3) Management | CAPI v1alpha3 (v0.3) Workload | CAPI v1alpha4 (v0.4) Management | CAPI v1alpha4 (v0.4) Workload | |
|---|---|---|---|---|
| Kubernetes v1.16 + kubeadm/v1beta2 | ✓ | ✓ | ||
| Kubernetes v1.17 + kubeadm/v1beta2 | ✓ | ✓ | ||
| Kubernetes v1.18 + kubeadm/v1beta2 | ✓ | ✓ | ✓ | |
| Kubernetes v1.19 + kubeadm/v1beta2 | ✓ | ✓ | ✓ | ✓ |
| Kubernetes v1.20 + kubeadm/v1beta2 | ✓ | ✓ | ✓ | ✓ |
| Kubernetes v1.21 + kubeadm/v1beta2 | ✓ | ✓ | ✓ | ✓ |
| Kubernetes v1.22 + kubeadm/v1beta2 (v0.3) kubeadm/v1beta3 (v0.4) | ✓ | ✓ | ✓ |
The Kubeadm Bootstrap Provider generates kubeadm configuration using the API version recommended for the target Kubernetes version.
Kubeadm Control Plane Provider (kubeadm-control-plane-controller)
| CAPI v1alpha3 (v0.3) Management | CAPI v1alpha3 (v0.3) Workload | CAPI v1alpha4 (v0.4) Management | CAPI v1alpha4 (v0.4) Workload | |
|---|---|---|---|---|
| Kubernetes v1.16 + etcd/v3 | ✓ | ✓ | ||
| Kubernetes v1.17 + etcd/v3 | ✓ | ✓ | ||
| Kubernetes v1.18 + etcd/v3 | ✓ | ✓ | ✓ | |
| Kubernetes v1.19 + etcd/v3 | ✓ | ✓ | ✓ | ✓ |
| Kubernetes v1.20 + etcd/v3 | ✓ | ✓ | ✓ | ✓ |
| Kubernetes v1.21 + etcd/v3 | ✓ | ✓ | ✓ | ✓ |
| Kubernetes v1.22 + etcd/v3 | ✓ | ✓ | ✓ |
The Kubeadm Control Plane Provider talks to the API server and etcd members of every Workload Cluster whose control plane it owns. It uses the etcd v3 API.
The Kubeadm Control Plane requires the Kubeadm Bootstrap Provider.
clusterctl
It is strongly recommended to always use the latest version of clusterctl, in order to get all the fixes/latest changes.
In case of upgrades, clusterctl should be upgraded first and then used to upgrade all the other components.
Providers Maintained By Independent Teams
In general, if a Provider version M says it is compatible with Cluster API version N, then version M must be compatible with a subset of the Kubernetes versions supported by Cluster API version N.
To understand the version compatibility of a specific provider, please see its documentation. This book includes a list of independent providers
Cluster API Roadmap
This roadmap is a constant work in progress, subject to frequent revision. Dates are approximations.
v0.4 (v1alpha4) ~ Q1 2021
| Area | Description | Issue/Proposal |
|---|---|---|
| Operator, Providers | Move to a single manager watching all namespaces for each provider | #3042 |
| Clusterctl | Redefine the scope of clusterctl move | #3354 |
| Extensibility | Support pluggable machine load balancers | #1250 |
| Core Improvements | Move away from corev1.ObjectReference | #2318 |
| Dependency | Kubeadm v1beta2 types and support | #2769 |
| UX, Bootstrap | Machine bootstrap failure detection with sentinel files | #3716 |
| Operator | Management cluster operator | #3427 |
| Features, KubeadmControlPlane | Support for MachineHealthCheck based remediation | #2976 |
| Features, KubeadmControlPlane | KubeadmControlPlane Spec should be fully mutable | #2083 |
| Testing, Clusterctl | Implement a new E2E test for verifying clusterctl upgrades | #3690 |
| UX, Kubeadm | Insulate users from kubeadm API version changes | #2769 |
| Cleanup | Generate v1alpha4 types, remove support for v1alpha2 | #3428 |
| Cleanup | Remove Status.Phase and other boolean fields in favor of conditions in all types | #3153 |
| Cleanup | Deprecate Status.{FailureMessage, FailureReason} in favor of conditions in types and contracts | #3692 |
| UX, Clusterctl | Support plugins in clusterctl to make provider-specific setup easier | #3255 |
| Tooling, Visibility | Distributed Tracing | #3760 |
| Bootstrap Improvements | Support composition of bootstrapping of kubeadm, cloud-init/ignition/talos/etc... and secrets transport | #3761 |
| Bootstrap Improvements | Add ignition support experiment as a bootstrap provider | #3430 |
| Integration | Autoscaler scale to and from zero | #2530 |
| API, Contracts | Support multiple kubeconfigs for a provider | #3661 |
| API, Networking | Http proxy support for egress traffic | #3751 |
| Features, Integration | Windows support for worker nodes | #3616 |
| Clusterctl, UX | Provide “at glance” view of cluster conditions | #3802 |
v0.5 (v1alpha5) ~ Q3 2021
| Area | Description | Issue/Proposal |
|---|
v1beta1/v1 ~ TBA
| Area | Description | Issue/Proposal |
|---|---|---|
| Maturity, Feedback | Submit the project for Kubernetes API Review | TBA |
Backlog
Items within this category have been identified as potential candidates for the project and can be moved up into a milestone if there is enough interest.
| Area | Description | Issue/Proposal |
|---|---|---|
| Security | Machine attestation for secure kubelet registration | #3762 |
| Conformance | Define Cluster API provider conformance | TBA |
| Core Improvements | Pluggable MachineDeployment upgrade strategies | #1754 |
| UX | Simplified cluster creation experience | #1227 |
| Bootstrap, Infrastructure | Document approaches for infrastructure providers to consider for securing sensitive bootstrap data | #1739 |